Automatic Sarcasm Detection with Prosodic Features
Andi Liu
Webber Academy
Grade 11
Presentation
Problem
Sarcasm is a statement which means the opposite of what is said (Cheang & Pell, 2008). Sarcasm is used because it is perceived as more polite than overtly negative statements, to avoid giving a clear answer or opinion, to show discontent with an exaggerated positive claim, and for humor (Arora, 2020; Cheang & Pell, 2008).
Several prosodic features have been identified to distinguish sarcastic and sincere utterances. When measuring across the whole sentence, sarcastic utterances have a lower mean fundamental frequency (F0) (Cheang & Pell, 2008). F0 measures pitch in Hertz; on average sarcastic utterances have a lower pitch than sincere ones (Koffi, 2024). Sarcasm also has a lower standard deviation (SD) and range of pitch. Sarcastic utterances were also expressed slower, with a lower syllable per second rate; and had a lower harmonic-noise ratio (HNR), indicating sarcastic utterances are hoarser and rougher (Cheang & Pell, 2008). Sarcastic sentences are often spoken with tension in the vocal apparatus and decreased salivation, producing a harsh tone that may be perceived as anger (Cheang & Pell, 2008; Scherer, 1986). A decreased F0 could be caused by a monotonic tone, which is a well cited indicator of sarcasm (Attardo et al., 2003; Rockwell, 2000). Pitch accents can also impact sarcasm perception. Sentences with a bitonal (L+H*) and elongated pitch accents are perceived as more sarcastic than those with a monotonal (H*) accent (Sheppard & Winters, 2022). Finally, sarcastic utterances often contain either compressed pitch, pronounced pitch, or within statement contrast (Attardo et al., 2003). Pitch range is suppressed throughout the utterance, or pitch accents are placed on every word and sometimes multiple syllables within a word. Alternatively, utterances with strong within statement contrast contain a phrase with high pitch range and a phrase with reduced pitch range. This pitch pattern usually manifests as a phrase with high pitch range followed by a phrase with extremely low pitch range (Attardo et al., 2003).
There are various applications for automatic sarcasm detection, including in sentiment analysis. Sentiment analysis is the use of machine learning to determine the attitude and emotion behind text (Sharma & Goyal, 2023). Sentiment analysis can classify text as generally positive, negative, or neutral; or as surprise, anger, fear, trust and joy (Mao et al., 2024; Rodríguez-Ibánez et al., 2023). Applications of this process include in government, to monitor public relations and the opinions of citizens on world events; in healthcare, to gauge patient reaction to treatment; and in computer science, to improve the responses of machine learning models like ChatGPT (Mao et al., 2024). The implicit emotions behind sarcasm can be perceived by humans through vocal cues and context (Mao et al., 2024). However, sentiment analysis does not consider sarcasm, creating the risk that a sarcastic statement could be misinterpreted as a positive one. A 50% decrease in sentiment analysis accuracy can be attributed to sarcasm (Sykora et al., 2020). Automatic sarcasm detection may improve the performance of sentiment analysis and make it more useful. Sarcasm detection can also benefit automatic speech recognition (ASR) systems. With the rise of home assistants like Amazon Alexa and Google Assistant, consumers are looking to talk to ASR systems with more casual speech. Because it's very likely that consumers will direct sarcasm towards people, events, or the ASR system itself, the ability for machines to recognize sarcastic speech may prove to be useful in the future to improve human-machine interaction (Gao et al., 2025; Rakov, 2019).
The inability of individuals to understand sarcasm can lead to miscommunication. Individuals who cannot understand sarcasm will interpret a sarcastic sentence literally. Difficulties in sarcasm comprehension are not uncommonly found after traumatic head injuries, right hemisphere strokes, and in individuals with schizophrenia and autism (Davis et al., 2016). Sarcasm detection can be applied to smartphone apps to detect sarcasm during a conversation or while watching a video, assisting these individuals in communication. Currently, machine learning models that detect sarcasm are mostly trained on text posts from Twitter and Reddit (Arora, 2020). Previous research shows that because sarcasm is also expressed through voice and not just the words themselves, detection that considers audio data is more accurate and has a lower error rate than models that consider text only. The inclusion of audio can reduce error rates by up to 12% (Bagga et al., 2024). Despite audio data improving detection, research on detecting sarcasm through audio is less common. By far the most popular datasets used for sarcasm detection by audio are the Multimodal Sarcasm Detection Dataset (MUStARD) and MUStARD++ datasets (Castro et al., 2019; Ray et al., 2022). The MUStARD dataset contains 600 labeled sarcastic and sincere utterances from popular sitcoms, while the MUStARD++ dataset contains 1202 utterances and is an extension of the MUStARD dataset (Bhosale et al., 2023; Castro et al., 2019; Ray et al., 2022).
Most research focused on sarcasm detection has been with neural networks (Bharti et al., 2022; Gao, Bansal, et al., 2024; Gao, Nayak, et al., 2024; Shi, 2024; Xue et al., 2024). However, neural networks are prone to overfitting compared to simpler models and may perform poorly on unseen data (Dreiseitl & Ohno-Machado, 2002). Neural networks are so-called “black box” models, models whose decision-making process is hard to interpret when making predictions. The inaccessibility of neural networks makes it difficult for users to understand why a model makes a prediction or to find biases and errors (Dreiseitl & Ohno-Machado, 2002; Hassija et al., 2024). The goal of linguistics is to understand how language works, (Portelance & Jasbi, 2024) but black-box models are not helpful in understanding what prosodic phenomena actually occur in sarcasm. The inner workings of simpler “white box” models like logistic regression are more transparent and interpretable (Dreiseitl & Ohno-Machado, 2002). Overfitting is not an issue and the contribution of certain features can also be measured, which is not possible in neural networks (Dreiseitl & Ohno-Machado, 2002; Hassija et al., 2024).
Current sarcasm detection models also use either Mel Frequency Cepstrum Coefficient (MFCC) or Wav2Vec to extract audio features (Bharti et al., 2022; Gao et al., 2025; Shi, 2024; Xue et al., 2024). MFCCs are based on spectrograms of speech, making them sensitive to noise in audio (Tracey et al., 2023). Noise sensitivity is not ideal if the model were to detect sarcasm in a loud environment. MFCCs also do not measure prosodic features that have been proven to be indicators of sarcasm, like pitch, amplitude, harmonic-to-noise ratio and speech rate (Bryant, 2010; Cheang & Pell, 2008). The use of features not supported by linguistics research also adds to the uninterpretability of detection models because there is no way to know if differences in MFCCs between sarcastic and sincere utterances are due to a real world linguistic phenomenon or bias from the dataset. Using prosodic features supported by research allows researchers to compare expression of the features in their dataset with other datasets, allowing them to detect bias in their dataset. There is a research gap in the use of simple machine learning models to detect sarcasm through audio on a large dataset. While previous research has used logistic regression to detect sarcasm from the TV show Daria, the applicability of the results are called into question given that only 150 utterances were used and all utterances came from one speaker (speaker-dependent) (Rakov, 2019).
This project applies both simple machine learning and prosodic features to a larger dataset, aiming at making the results more reliable and linguistically informed. The short term goals of this study is to create a logistic regression model that distinguishes sarcastic and sincere phrases from prosodic features and to characterise differences in prosody between sarcastic and sincere utterances. The long term goal is to use the model to develop a computer app that detects sarcasm in real time from conversations. This will help individuals who cannot identify sarcasm understand the meaning of speech and help them better communicate with others. The research question is as follows:
- Can a simple logistic regression model perform at an equal level as neural networks when detecting sarcasm from speech?
Method
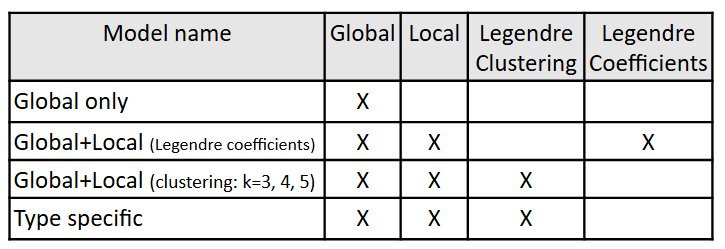
 Feature inclusion: features with p < 0.05 in training set
Feature inclusion: features with p < 0.05 in training set
Legendre Coefficient → simplification of pitch/intensity contour
K-means Clustering → reduction of Legendre coefficients to discrete values
Analysis





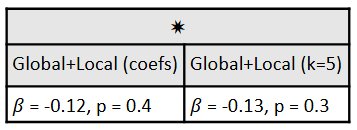

 Legendre coefficients
Legendre coefficients
- Not predictive or sarcasm types → pitch + intensity contours not distinct enough/difference not on prominent word
- (Sheppard & Winters, 2022) found contribution of contour shape on sarcasm perception, not production
- (Chen & Boves, 2018) found FPC of contours to be predictive in detection of British English → possible impact of dialect + representation method
Speech rate
- Difference in speech rate predictor in more variable models only → weak predictor
- Speech rate of prominent word slower in exaggerated sarcasm → possibly adds additional emphasis
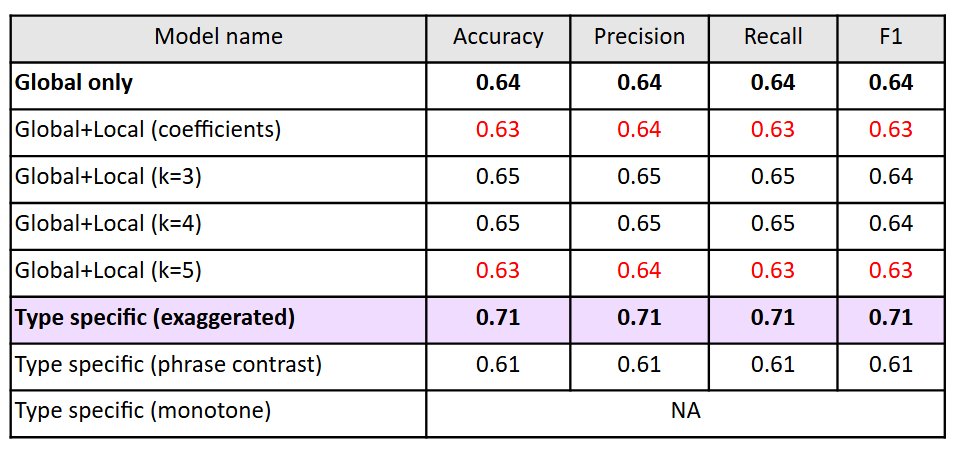
Sarcasm type
- Performance differs substantially by sarcasm type
- Monotone Sarcasm not different from Sincere → prosodically similar, importance of meaning
- Within-phrase Sarcasm model low performance→ type characterized by “sincere” part + “sarcastic” part
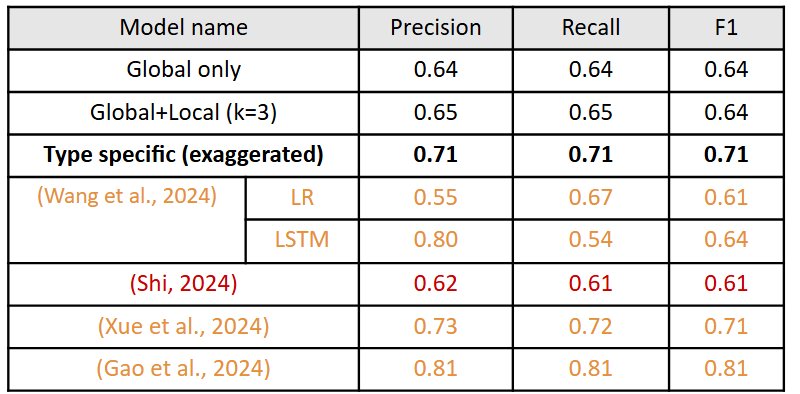
Comparison to other models
Performance of best model comparable to other models trained on MUStARD
Orange = multimodal (audio + text), Red = audio only
Conclusion
- Best performing model comparable to others in field → Yes to RQ
- Sarcasm type influences system performance → need of type sensitive systems (eg. multimodal with text in monotone type)
- Potential of LR to be effective in sarcasm detection → prosody based features useful in sarcasm detection
Future direction: FPC, Wavelet for automatic prominence detection, comparison to conversational sarcasm, include text to improve performance on monotone type
Sources of error: speakers “acting sarcastic” → prosodic differences bigger; noise in audio
No generative AI was used in the development or documentation of this project
Citations
Image:
Gauld, T. (2020). Tom Gauld’s Attempts To Create A Sarcastic AI Are Really Genius [Cartoon]. https://www.newscientist.com/article/0-tom-gaulds-attempts-to-create-a-sarcastic-ai-are-really-genius/
MUStARD++ dataset:
Ray, A., Mishra, S., Nunna, A., & Bhattacharyya, Pushpak . (2022). A Multimodal Corpus for Emotion Recognition in Sarcasm. Proceedings of the 13th Conference on Language Resources and Evaluation (LREC 2022), 6992–7003. https://aclanthology.org/2022.lrec-1.756.pdf
(1) Attardo, S., Eisterhold, J., Hay, J., & Poggi, I. (2003). Multimodal markers of irony and sarcasm. Humor: International Journal of Humor Research, 16(2), 243–260. https://doi.org/10.1515/humr.2003.012
(2) Sheppard, B., & Winters, S. (2022). Effects of speaking rate and pitch accent types on the perception of verbal irony [Honours Thesis]. University of Calgary.
(3) Chen, A., & Boves, L. (2018). What’s in a word: Sounding sarcastic in British English. Journal of the International Phonetic Association, 48(1), 57–76. https://doi.org/10.1017/S0025100318000038
(4) Wang, Y., Huang, Z., Gandhi, M., & Chen, H. C. (2024). Multimodal Sarcasm Detection Based on MUStARD Dataset [Masters, University of Pennsylvania]. https://monagandhi09.github.io/asset/pdf/SarcasmDetector.pdf
(5) Shi, E. (2024). Multimodal Sarcasm Detection Using BERT, TimesFormer, and Wav2Vec 2.0 with MUStARD++ [Masters]. University of Groningen.
(6) Xue, H., Xu, L., Tong, Y., Li, R., Lin, J., & Jiang, D. (2024). Breakthrough from nuance and inconsistency: Enhancing multimodal sarcasm detection with context-aware self-attention fusion and word weight calculation. In N. Calzolari, M.-Y. Kan, V. Hoste, A. Lenci, S. Sakti, & N. Xue (Eds.), Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (pp. 2493–2503). ELRA and ICCL. https://aclanthology.org/2024.lrec-main.224
(7) Gao, X., Bansal, S., Gowda, K., Li, Z., Nayak, S., Kumar, N., & Coler, M. (2024). AMuSeD: An attentive deep neural network for multimodal sarcasm detection incorporating bi-modal data augmentation. arXiv. https://doi.org/10.48550/ARXIV.2412.10103




Acknowledgement
Special thanks goes to Brooklyn Sheppard and Angeliki Athanasopoulou from the University of Calgary for their mentorship. Appreciation is also extended to Dr Garcia and Ms Kale