Testing the for the best algorithm for teaching Artificial Intelligence
Viacheslav Roman
Tom Baines School
Grade 6
Presentation
No video provided
Hypothesis
I think the Mean squared error and sigmoid function will lower the most effectivly loss, because they are the most common. and Relu and Mean squared error catch up since relu is simple
Research
I researched and found there to be 3 types of AIs in general, supervised are trained with examples that are labeled, meaning after results are in, the AI answer can be checked with the label and a cost will be calculated, unsupervised AIs are just feed with data, they are expected to find patterns on its own, and deep reinfocment, they learn through trial and error(so does supervisedand other types, but deep reinfocment is reffered as learning through trial and error more often) where its trained to take in sometimes very large inputs(e.g. Pixels of a video game) to then maximize a value(e.g. Video game score), it is one of the more dynamic networks, as it has been applied to farm more concpets, like robotics, video games, natural language processing, computer vision education, transportation, finance and healthcare.
Variables
| Independent variables | Dependent variables | Control variables |
|---|---|---|
| Cost calculation | Cost(or rewards) | Dataset(or environment for deep-reinforcment learning |
| Activation function | Time spent training | |
| Size of network | Main frame(how I code most of the stuff I wont change) | |
| Labeling | Inputs for each type | |
| Learning rate(this isnt a dependent variable) | Batch size | |
| Each independent variable will get changed induvidually | ||
Procedure
Supervised:
- I will code a network, that uses MNIST dataset to train it, and after each batch, I will record its cost(loss), then I willl graph it(for visuals)
- After it is trained, I will calculate its accuracy(in percentages)
- Now, I'll change 1 thing, and redo steps 1-3 until i go through a variety of combinations
- I will determine the best one based on accuracy
Unsupervised:
- I will reuse my previous network, with changes so that instead of using known labels, it will use clustering, meaning it groups images that are simular, meaning it will probably learn to identify digits without any direction, again, record after every batch
- I will then calculate its accuracy, and by that, it might think all nines are ones, but thats expected, as long as it is confident in something for all of the same digits, i will count it correctly
- After that, I will again change 1 thing and redo 1-3
- The winner will be the most accurate one
Deep-reinfocment:
- I will yet again reuse my network, and pong which i coded a while ago, I will modify pong so instead of taking user input, it will tell the ai where the ball is and where is it heading every frame, and the ai will deice to go right or left, mainly what changes in the network is the cost, beacuse maybe it had done 3 actions to get to the reward, and currently, the cost only takes in a target and an output for the network
- I will record after each batch, and after training i will calculate its average reward(score) over 250 games of pong
- Then again, I will change 1 thing and redo 1-3
- The best one will be the one with the greatest average reward(score)
Observations
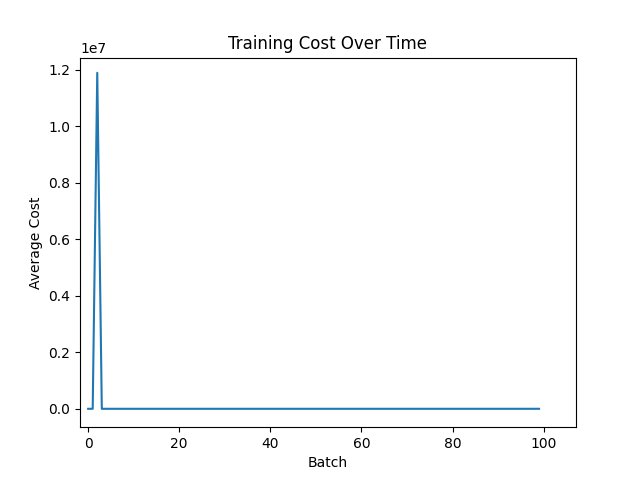
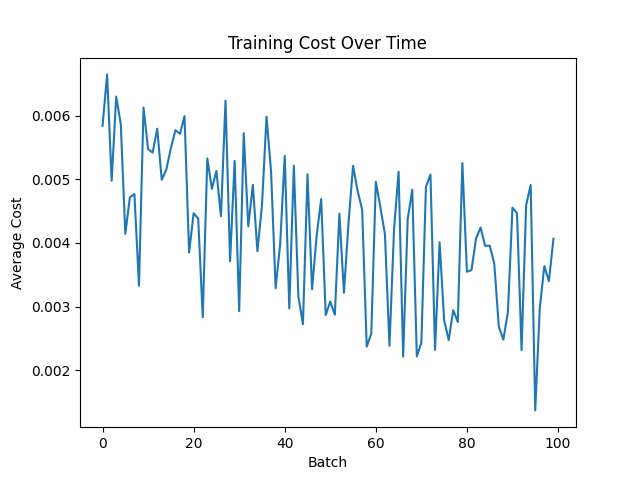
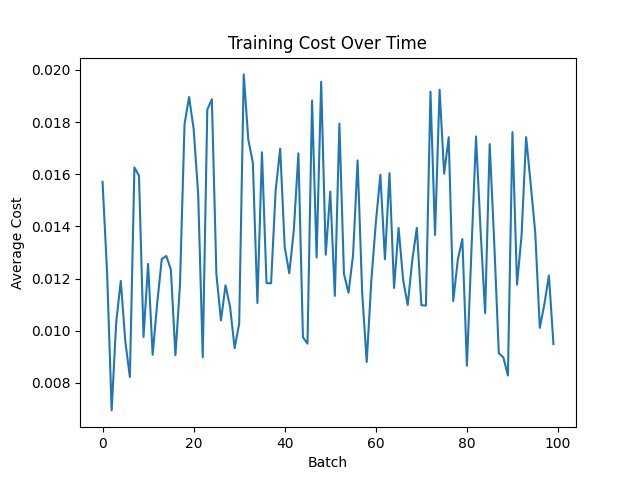
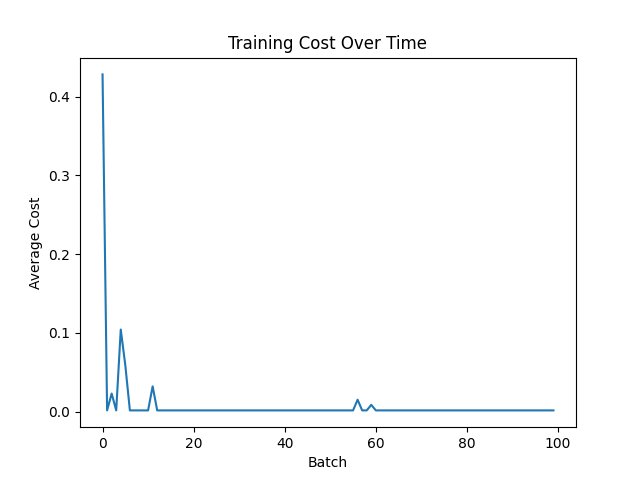
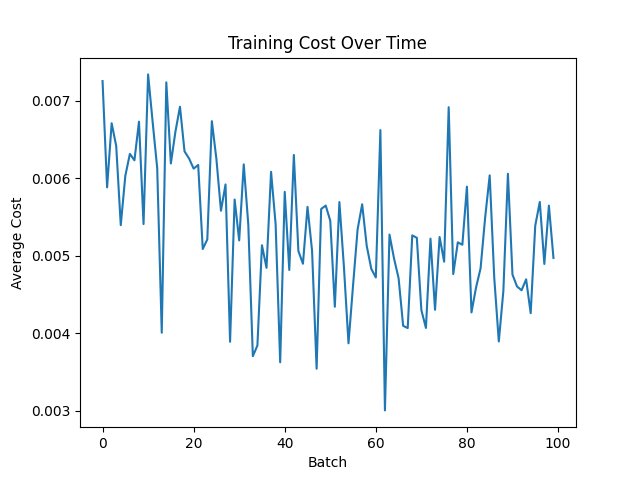
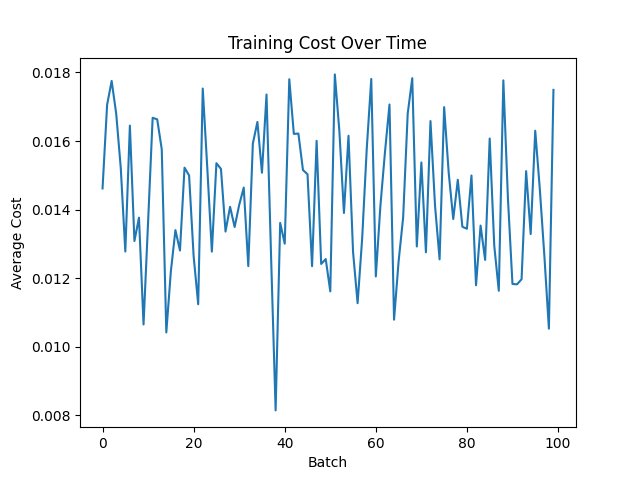
| Function | Figue number from top |
|---|---|
| MSE with ReLu | 1 |
| MSE with Sigmoid | 2 |
| MSE with tahn | 3 |
| MAE with ReLu | 4 |
| MAE with Sigmoid | 5 |
| MAE with tahn | 6 |
Analysis
The MSE with ReLu combination decreases it quickly, most likely sin the result is already near 0 or 0 because of the way the wieghts are intioalized The others, excluding MAE with Relu, which exphits simular behavior to MSE with ReLu, are more "jumpy", that is becuase, first, they mostly had no big loss jumps so the graph was smaller, and second, they work squish it into a range, like tahn squishes to -1 to 1 and sigmoid squishes to 0 to 1, notice i said squishes, mean it is reversable, unlike Relu, so it must be more jumpy, so that you can revrse it and due to this analisys, it it likely that for other types of networks, unsupervised and deep-reinforcment, behavior will be similar
Conclusion
Relu might seem like a winner, but it hangs around 0.018, but MSE with Sigmoid is at arround 0.004, granting us a winner, but if you want quicker result and more relibable, becuase if you stop at a batch where MSE with Sigmoid is high, than you will get poorer results.
Application
this can be used for mainly recontion, of coruse, for example, making sure a person can go to diffirent places without a passport, just scan a face, it finds their id, and BOOM, they are free to go, and scanning words/numbers, for example, you have a bad camera, and your lighting isnt good, you can have this neural network scan it, and increase quilty to allow seeing words.
Sources Of Error
The biggest one, is while intioalizing the weights, they were randomized, other than that, everything was under control(no seriously, this is code, i had PERFECT control while changing independent variables)
Citations
https://www.ibm.com/think/topics/neural-networks https://www.geeksforgeeks.org/deep-learning/loss-functions-in-deep-learning/ https://neuralnets.dev/posts/deep-learning/loss-and-activations/
Acknowledgement
Thanks to 3Blue1Brown's channel on youtube, it is truly one of the greatest sources to understanding neural network. https://www.youtube.com/@3blue1brown