
The Power of AI in Medicine - Using Machine Learning to Predict Cancer Diagnoses and Outcomes
Grade 11
Presentation
No video provided
Problem
INTRODUCTION - ABSTRACT
Cancer remains a significant global health burden, with millions of deaths occurring annually. A major challenge in combating cancer lies in the timely and accurate diagnosis, which can be hindered by the vast amount of electronic health data generated during patient encounters, including laboratory tests, imaging studies, and genomic analyses. This data, often referred to as "big data," exceeds the capacity of traditional statistical methods and overwhelms individual healthcare providers attempting manual interpretation. However, artificial intelligence (AI) technologies, particularly machine learning, offer promising solutions to this problem. By leveraging historical data to discern patterns and develop predictive models, machine learning algorithms can aid in diagnosing cancer and forecasting patient outcomes. This approach enables the identification of high-risk individuals who may benefit from early interventions, facilitating personalized care strategies tailored to individual patient profiles. This project explores the application of AI in cancer care, emphasizing the potential for improved patient outcomes and reduced morbidity and mortality through early detection and targeted interventions.
PROBLEM
What is Machine Learning and How Can it be Utilized to Optimise Cancer Diagnosis, Prognosis, and Treatment?
HYPOTHESIS
I believe that machine learning (ML) offers promising avenues for optimizing cancer diagnosis, prognosis, and treatment. By leveraging vast amounts of data to identify patterns and insights, ML technologies have the potential to completely surpass the capabilities of human analysis alone. Through sophisticated algorithms, machine learning models may analyze complex medical datasets, including patient demographics, genetic information, medical imaging, and treatment outcomes, and go on to develop predictive models and decision-support systems tailored to individual patients. By integrating machine learning into clinical workflows, healthcare providers can also potentially enhance the accuracy and efficiency of cancer diagnosis, predict patient outcomes more accurately, and personalize treatment plans based on an individual's unique characteristics and disease profile. Ultimately, I think that the strategic implementation of machine learning technologies holds the potential to revolutionize cancer care, ultimately leading to improved patient outcomes and better allocation of healthcare resources.
Method
For my research project, I will adopt a methodology that revolves around the analysis of existing scientific literature and resources.
Initially, I will dedicate time to comprehensively understanding the foundational principles of both machine learning and oncology. This preliminary stage will involve delving into the core concepts of each discipline to establish a groundwork for the rest of my research. Through this process, I aim to thoroughly understand how machine learning operates and its applications within the field of oncology.
With a solid foundation in place, I will proceed to formulate specific research inquiries aimed at probing into key areas of interest. These questions will revolve around explaining the primary machine-learning techniques employed in cancer diagnosis, evaluating the efficacy of machine-learning models in predicting cancer diagnosis and prognosis, and examining the challenges associated with integrating machine learning into clinical practice to optimize treatment strategies. To address these inquiries, I will conduct a further thorough analysis of relevant literature, encompassing existing models, research articles, and clinical studies sourced from reputable online platforms.
After thoroughly reviewing the existing literature, my next step is to create my own custom machine-learning model algorithm. Using online datasets, I'll design a specific model to demonstrate how machine learning can be applied in healthcare. This model would aim to showcase the practical benefits of machine learning in healthcare while highlighting its potential to transform medical practices. Ultimately, my goal is to contribute to the understanding of integrating machine learning in oncology, advancing our knowledge of its impact on clinical decision-making and patient care.
Research
MACHINE LEARNING
WHAT IS MACHINE LEARNING?
Machine learning, a subset of artificial intelligence (AI), is a rapidly evolving field that empowers computers to learn from data and improve their performance without being explicitly programmed. At its core, machine learning revolves around developing algorithms that enable systems to recognize patterns within data and make predictions or decisions based on those patterns. This approach contrasts with traditional programming paradigms, where explicit instructions dictate the system's behavior. Instead, in machine learning, algorithms iteratively learn from data, uncovering insights, and adapting their model to improve performance over time.
The fundamental concept behind machine learning is the ability of algorithms to generalize from examples. Instead of relying solely on rules defined by programmers, machine learning algorithms can automatically adjust their parameters based on the input data, enabling them to make accurate predictions or decisions on new, unseen data. This process is often described as "learning" because the algorithms iteratively refine their internal representations of the data, gradually improving their performance over time.
STEPS TO CREATING A MACHINE LEARNING ALGORITHM
The general framework of machine learning models is based on a series of steps, as follows:
- Data Collection and Preprocessing: Machine learning begins with data. This data can come from various sources such as sensors, databases, or even manual entry. Before feeding the data into a machine learning algorithm, it often needs to be cleaned and preprocessed. This involves tasks like removing outliers, handling missing values, normalizing or scaling features, and encoding categorical variables.
- Feature Engineering: Feature engineering is the process of selecting, transforming, or creating new features from the raw data to improve the performance of the machine learning model. This might involve techniques like feature scaling, dimensionality reduction, or creating new features through domain knowledge.
- Model Selection: Choosing the right model architecture or algorithm is crucial for the success of a machine learning project. Factors to consider include the nature of the data, the complexity of the problem, computational resources, and interpretability requirements. Common models include decision trees, support vector machines, neural networks, and ensemble methods like random forests and gradient boosting.
- Training: Training a machine learning model involves feeding it with data and adjusting its internal parameters to allow it to generalize the training data, capturing patterns that enable it to make predictions or decisions on new, unseen data.
- Evaluation: Evaluating the performance of a machine learning model is essential to assess its effectiveness and generalization ability. This is typically done using metrics tailored to the specific task, such as accuracy, precision, recall, F1-score, mean squared error, or area under the ROC curve (AUC-ROC). Cross-validation techniques like k-fold cross-validation or holdout validation are often used to obtain reliable estimates of a model's performance.
- Hyperparameter Tuning: Machine learning models often have hyperparameters that need to be set before training, such as learning rate, regularization strength, or tree depth. Hyperparameter tuning involves searching for the optimal combination of hyperparameters to maximize the model's performance. Techniques like grid search, random search, or Bayesian optimization are commonly used for hyperparameter tuning.
- Deployment and Monitoring: Once a model has been trained and evaluated, it can be deployed into production to make predictions on new data. However, the deployment process doesn't end there. Models need to be monitored and maintained over time to ensure they continue to perform well as data distributions shift or new patterns emerge. This may involve retraining the model periodically, updating it with new data, or incorporating feedback from users.
COMMON MACHINE LEARNING ALGORITHMS
There are numerous machine learning algorithms, each designed to solve specific types of problems and suited to different types of data. Here's a list of some commonly used machine learning algorithms:
Linear Regression:
- Purpose: Predicting a continuous value based on one or more input features.
- Operation: Fits a line (or hyperplane) to the data, minimizing the distance between the observed values and the predicted values.
Logistic Regression:
- Purpose: Predicting the probability of a binary outcome.
- Operation: Models the probability of the default class using a logistic function, which maps the output to the range [0, 1].
Decision Trees:
- Purpose: Classification and regression tasks by partitioning the feature space.
- Operation: Splits the data based on features to minimize impurity (e.g., Gini impurity or entropy) and makes predictions based on the majority class or average target value within each region.
Random Forest:
- Purpose: Combining multiple decision trees to improve accuracy and reduce overfitting.
- Operation: Builds multiple decision trees on random subsets of the data and combines their predictions through averaging or voting.
K-Nearest Neighbors (KNN):
- Purpose: Making predictions based on the majority class of the k nearest neighbours in the feature space.
- Operation: Stores all available cases and classifies new cases based on a similarity measure (e.g., Euclidean distance).
K-Means Clustering:
- Purpose: Unsupervised learning algorithm for clustering similar data points into a predefined number of clusters.
- Operation: Iteratively assigns data points to the nearest cluster centroid and updates the centroids based on the mean of the assigned points.
SUPERVISED TRAINING IN MACHINE LEARNING
Supervised learning is a fundamental paradigm in machine learning where algorithms learn from labelled data, meaning each training example is paired with an associated label or target output. The goal of supervised learning is to learn a mapping from input features to output labels, allowing the algorithm to make predictions or decisions on new, unseen data.
In supervised learning, the training process involves presenting the algorithm with a dataset containing input-output pairs. The algorithm learns from these examples by adjusting its internal parameters to minimize the difference between its predictions and the true labels. This process typically involves an optimization algorithm, such as gradient descent, which iteratively updates the model parameters to reduce a loss function that quantifies the difference between predicted and actual outcomes.
There are two main types of supervised learning tasks: classification and regression.
- In classification tasks, the goal is to assign input data points to discrete categories or classes. For example, a spam email classifier might categorize emails as either spam or not spam based on features extracted from the email content. Common algorithms used for classification include logistic regression, decision trees, random forests, support vector machines, and neural networks.
- In regression tasks, the goal is to predict a continuous-valued output based on input features. For instance, predicting house prices based on features such as size, location, and number of bedrooms is a regression problem. Regression algorithms include linear regression, polynomial regression, decision trees, and neural networks.
Supervised learning has been the focus of extensive research and development, resulting in a wide range of algorithms and techniques tailored to different types of data and problem domains. The availability of labelled data is often a critical factor in the success of supervised learning projects, as models require sufficient examples to learn meaningful patterns and relationships.
Despite its successes, supervised learning also faces challenges, such as overfitting (where the model memorizes the training data instead of learning generalizable patterns) and the need for large amounts of labelled data for training. Researchers continually work to address these challenges and improve the performance and scalability of supervised learning algorithms, driving innovation and progress in the field of machine learning.
UNSUPERVISED TRAINING IN MACHINE LEARNING
Unsupervised learning is a branch of machine learning where algorithms are trained on unlabeled data, meaning the input data lacks explicit output labels or target variables. Instead of predicting specific outputs, unsupervised learning algorithms seek to uncover underlying patterns, structures, or relationships within the data. The absence of labelled data distinguishes unsupervised learning from supervised learning, making it particularly useful in scenarios where obtaining labelled data may be difficult, expensive, or impractical. Unsupervised learning techniques can be broadly categorized into clustering, dimensionality reduction, and anomaly detection:
- Clustering: Clustering algorithms group similar data points together into clusters based on their intrinsic properties or relationships. The goal is to identify natural groupings or partitions within the data without prior knowledge of the class labels. Examples of clustering algorithms include k-means clustering, hierarchical clustering, and Gaussian mixture models. Clustering finds applications in market segmentation, customer profiling, image segmentation, and document clustering.
- Dimensionality Reduction: Dimensionality reduction techniques aim to reduce the number of features or variables in a dataset while preserving its essential structure and information. By reducing the dimensionality of the data, these techniques can simplify complex datasets, remove redundant information, and facilitate visualization and interpretation. Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and autoencoders are common dimensionality reduction methods used in unsupervised learning. Dimensionality reduction is valuable in exploratory data analysis, feature engineering, and data compression.
- Anomaly Detection: Anomaly detection, also known as outlier detection, involves identifying data points that deviate significantly from the norm or expected behavior within a dataset. Anomalies may represent rare events, errors, or outliers that require further investigation. Unsupervised anomaly detection algorithms aim to distinguish between normal and abnormal instances without explicit supervision. Techniques such as isolation forests, k-nearest neighbors (k-NN), and Gaussian mixture models can be used for anomaly detection. Applications of anomaly detection include fraud detection, network security, fault detection in industrial systems, and healthcare monitoring.
Unsupervised learning techniques have diverse applications across various domains and are often used in combination with supervised learning methods for comprehensive data analysis. However, evaluating the performance of unsupervised learning algorithms can be challenging since there are no explicit labels to measure predictive accuracy. In any case, ongoing research in unsupervised learning continues to advance the development of innovative algorithms and techniques. Eventually, it holds the power to become a crucial tool for extracting meaningful insights, discovering hidden patterns, and gaining a deeper understanding of data structures.
REINFORCEMENT TRAINING IN MACHINE LEARNING
Reinforcement learning is a branch of machine learning that concerns teaching agents to make sequential decisions in an environment to achieve specific goals. Unlike supervised and unsupervised learning, where the algorithm learns from labelled or unlabeled data, reinforcement learning agents learn through trial and error by interacting with their environment and receiving feedback in the form of rewards or penalties.
The fundamental components of reinforcement learning include:
- Agent: The learner or decision-maker that interacts with the environment. The agent selects actions based on its policy, which defines the mapping from states to actions.
- Environment: The external system with which the agent interacts. It provides feedback to the agent in response to its actions and may change states accordingly.
- State: A representation of the current situation or configuration of the environment. The state provides the context for the agent's decision-making process.
- Action: The choices available to the agent at each state. The agent selects actions based on its current policy, aiming to maximize long-term rewards.
- Reward: Feedback provided by the environment to the agent after each action. Rewards represent the immediate feedback signal that guides the agent's learning process.
The goal of reinforcement learning is to learn an optimal policy that maximizes the cumulative reward over time. To achieve this, reinforcement learning algorithms typically use one of two approaches:
- Value-Based Methods: These methods aim to estimate the value of each state or state-action pair, indicating how desirable it is to be in that state or take that action. Value-based methods use techniques such as Q-learning and deep Q-networks (DQN) to learn the optimal value function, which informs the agent's decision-making process.
- Policy-Based Methods: These methods directly learn the optimal policy without explicitly estimating the value function. Policy-based methods parameterize the policy directly and use techniques such as policy gradients and actor-critic methods to update the policy based on the observed rewards.
USES OF MACHINE LEARNING
Machine learning (ML) has a wide range of applications across various fields. Some common and notable uses of machine learning include:
-
Predictive Analytics: ML algorithms can be used to predict outcomes based on historical data. This is used in finance for stock price prediction, in healthcare for disease prognosis, and in marketing for customer behavior prediction.
-
Natural Language Processing (NLP): ML techniques are used to understand and interpret human language. This includes sentiment analysis, language translation, chatbots, and text summarization.
-
Image Recognition and Computer Vision: ML algorithms can be trained to recognize patterns and objects within images or videos. Applications include facial recognition, object detection, autonomous vehicles, and medical imaging analysis.
-
Recommendation Systems: ML is used to predict and suggest items or content that users might like based on their past behavior or preferences. Examples include movie recommendations on streaming platforms and product recommendations on e-commerce websites.
-
Fraud Detection: ML algorithms can detect fraudulent activities by identifying patterns of unusual behavior. This is widely used in banking and finance to detect credit card fraud, identity theft, and other types of fraudulent transactions.
-
Autonomous Vehicles: ML algorithms are crucial for self-driving cars to perceive their environment, make decisions, and navigate safely. This involves processing sensor data such as cameras, lidar, and radar.
-
Robotics: ML is used in robotics for tasks such as object manipulation, path planning, and learning from interactions with the environment.
-
Financial Trading: ML algorithms are used for algorithmic trading, where they analyze market data and execute trades automatically based on predefined strategies.
-
Virtual Personal Assistants: ML powers virtual assistants like Siri, Alexa, and Google Assistant, enabling them to understand and respond to voice commands, schedule appointments, set reminders, and provide personalized recommendations.
These are just a few examples, and the applications of machine learning continue to expand across various industries as the technology advances.
ONCOLOGY
CANCER OVERVIEW
Cancer is a disease in which some of the body’s cells grow uncontrollably and spread to other parts of the body. Cancer can start almost anywhere in the human body, which is made up of trillions of cells. Normally, human cells grow and multiply (through a process called cell division) to form new cells as the body needs them. When cells grow old or become damaged, they die, and new cells take their place (this degrades with age). Sometimes this orderly process breaks down, and abnormal or damaged cells grow and multiply when they shouldn’t. These cells may form tumours, which are lumps of tissue. Tumours can be cancerous (malignant) or not cancerous (benign).
In a broader view, Cancer is a genetic disease meaning that it is caused by changes to genes that control the way our cells function, especially how they grow and divide.
Genetic changes that cause cancer can happen because of:
- Errors that occur as cells divide
- Damage to DNA caused by harmful substances in the environment, such as the chemicals in tobacco smoke and ultraviolet rays from the sun
- Inheritance from our parents
That being said, each person’s cancer has a unique combination of genetic changes. As cancer continues to grow, additional changes will occur. Due to this heterogeneity, detecting cancers can become extremely difficult. This is where testing comes into play:
- Screening tests play a vital role in detecting cancer before symptoms appear. These tests are designed to identify abnormalities or signs of cancer in people who are not yet experiencing symptoms. For instance, mammograms are used for breast cancer screening, while colonoscopies are employed for colorectal cancer detection.
- Diagnostic tests are utilized when symptoms or screening results suggest the presence of cancer. These tests aim to confirm the diagnosis and provide information about the cancer's type, location, and stage. Biopsies, imaging scans like CT scans or MRIs, and blood tests such as tumour marker tests are commonly used diagnostic tools.
TYPES OF MEDICAL DATA IN ONCOLOGY (DIAGNOSIS)
In the field of oncology, there are numerous tests and types of data used for diagnosing, staging, monitoring, and treating cancer. Here are some common ones:
- Biopsy: A biopsy involves removing a sample of tissue or cells from the body to examine them under a microscope. It's one of the most definitive ways to diagnose cancer and determine its type and grade.
- Imaging tests: Various imaging techniques are used to visualize tumours and assess their size, location, and spread. Common imaging tests include X-rays, CT scans, MRI scans, PET scans, ultrasound, and mammograms.
- Blood tests: Blood tests can provide information about the overall health of a patient and specific markers that may indicate the presence of cancer. Examples include complete blood count (CBC), tumour markers (e.g., PSA for prostate cancer, CA-125 for ovarian cancer), and genetic tests.
- Pathology reports: Pathologists analyze biopsy samples and provide detailed reports on the characteristics of cancer cells, such as their size, shape, and degree of abnormality. This information helps guide treatment decisions and prognosis.
- Genomic testing: Genomic testing examines the DNA of cancer cells to identify specific mutations or genetic alterations that may influence treatment options and prognosis. Techniques like next-generation sequencing (NGS) are commonly used for this purpose.
- Tumor grading and staging: Tumor grading assesses the aggressiveness of cancer cells based on their appearance under a microscope, while staging determines the extent of cancer spread in the body. Staging often involves imaging tests, surgical exploration, and examination of lymph nodes.
- Liquid biopsy: Liquid biopsy involves analyzing blood or other bodily fluids to detect circulating tumour cells, cell-free DNA, or other biomarkers released by tumours. It can provide real-time information about cancer status and help monitor treatment response and resistance.
- Functional tests: Functional tests assess how well certain organs or systems are functioning in the context of cancer diagnosis and treatment. Examples include tests of liver function, kidney function, and cardiac function.
While there are many other tests and the medical data will vary from patient to patient, these are just some of the common tests which are seen in oncology research. Being able to utilize these tests and their data effectively plays a key role in a patient’s diagnosis, prognosis, and treatment.
Example of MRI (Form of Medical Data Often Used in Diagnostics)
WHY DO CURRENT DIAGNOSTIC TOOLS NEED TO IMPROVE?
Cancer diagnosis is a critical aspect of managing and treating cancer effectively. While current diagnostic methods have advanced significantly over the years, there are still several reasons why further improvements are needed:
-
Early Detection: Many cancers can be more effectively treated if detected at an early stage. Improved diagnostic methods could help identify cancerous cells or tumours at an earlier point in their development, potentially leading to better treatment outcomes and higher survival rates.
-
Accuracy: Current diagnostic techniques, such as imaging tests and biopsies, may not always provide a definitive diagnosis or may yield false positives or false negatives. Improved methods could enhance accuracy, reducing the likelihood of misdiagnosis and unnecessary treatments or delays in treatment initiation.
-
Accessibility: Some diagnostic tests can be expensive, invasive, or require specialized equipment and expertise, limiting their accessibility, especially in resource-limited settings. Developing simpler, more affordable, and widely available diagnostic tools could improve access to timely cancer diagnosis for more people worldwide.
-
Personalized Medicine: Advances in cancer research have highlighted the importance of personalized treatment approaches tailored to individual patient's unique characteristics, including their genetic makeup and tumour biology. Improved diagnostic methods could provide more detailed information about the specific features of each patient's cancer, enabling personalized treatment strategies to be implemented more effectively.
-
Monitoring Treatment Response: Effective cancer management often involves monitoring how tumours respond to treatment over time. Current methods for assessing treatment response may be limited in their sensitivity or specificity. Enhanced diagnostic techniques could enable more accurate and timely evaluation of treatment effectiveness, allowing for adjustments to therapy as needed.
-
Detection of Minimal Residual Disease: Even after successful treatment, there may still be residual cancer cells present in the body. Detecting these minimal residual disease (MRD) states is crucial for preventing cancer recurrence. Improved diagnostic methods with greater sensitivity could aid in detecting MRD earlier and more accurately, potentially improving long-term outcomes for cancer survivors.
Overall, by addressing these challenges and continuing to innovate in cancer diagnostics, we can strive to improve patient outcomes, reduce the burden of cancer, and ultimately contribute to the advancement of cancer care.
APPLICATION
MACHINE LEARNING ALGORITHMS EMPLOYED IN CANCER DIAGNOSIS
Machine learning techniques have become increasingly important in cancer diagnosis due to their ability to analyze large datasets and identify patterns that may not be apparent to human experts. Some primary machine learning techniques employed in cancer diagnosis include:
-
Supervised Learning:
-
Support Vector Machines (SVM): SVMs are powerful classifiers used in cancer diagnosis due to their ability to handle high-dimensional data and find optimal decision boundaries. In cancer diagnosis, SVMs are applied to various types of data, including gene expression profiles, histopathology images, and clinical data. SVMs have been particularly effective in tasks such as distinguishing between benign and malignant tumors, classifying cancer subtypes, and predicting patient outcomes.
-
Random Forests: Random forests are ensemble learning methods that combine multiple decision trees to improve classification accuracy and robustness. In cancer diagnosis, random forests are used to analyze complex datasets containing a large number of features. They are particularly suitable for tasks such as identifying biomarkers associated with specific cancer types, predicting patient survival, and detecting rare subtypes of cancer.
-
Logistic Regression: Logistic regression is a simple yet effective algorithm used for binary classification tasks in cancer diagnosis. It models the probability of an event occurring based on one or more predictor variables. In cancer diagnosis, logistic regression models are applied to predict the likelihood of a patient having cancer or to classify tumours into different subtypes based on features extracted from genomic, imaging, or clinical data.
-
-
Unsupervised Learning:
-
Clustering Algorithms (e.g., K-means, Hierarchical Clustering): Clustering algorithms are used to group similar data points together based on some similarity metric. In cancer diagnosis, clustering techniques are applied to identify intrinsic subtypes of cancer based on molecular profiles or clinical characteristics. Clustering can also be used to stratify patients into groups with similar prognosis or treatment response, enabling personalized medicine approaches.
-
Principal Component Analysis (PCA): PCA is a dimensionality reduction technique used to reduce the number of variables in a dataset while preserving most of the information. In cancer diagnosis, PCA is applied to identify the most informative features or to visualize high-dimensional data in lower dimensions. PCA can help uncover underlying patterns in complex datasets, facilitating data interpretation and feature selection in cancer research.
-
-
Reinforced Learning:
-
Convolutional Neural Networks (CNNs): CNNs are deep learning architectures widely used in cancer diagnosis for image analysis tasks. In histopathology, CNNs are applied to detect and classify tumours based on tissue images. In medical imaging, CNNs are used to analyze MRI, CT, or PET scans for early detection and staging of cancer. CNNs can automatically learn hierarchical representations from raw image data, enabling accurate and efficient diagnosis of cancer.
-
Recurrent Neural Networks (RNNs): RNNs are neural network architectures suitable for sequential data analysis. In cancer diagnosis, RNNs are applied to analyze genomic sequences, time-series data (e.g., patient monitoring data), or electronic health records (EHRs). RNNs can capture temporal dependencies in data and predict disease progression, treatment response, or patient outcomes. They have the potential to uncover hidden patterns in longitudinal patient data that may be overlooked by traditional methods.
-
-
Semi-Supervised Learning:
-
Gradient Boosting Machines (GBM): GBM is an ensemble learning technique that combines multiple weak learners (typically decision trees) to create a strong predictive model. In cancer diagnosis, GBM is used to integrate information from diverse sources (e.g., genomic data, imaging data, clinical data) and improve predictive accuracy. GBM models can identify important features associated with cancer progression, treatment response, or patient survival, facilitating personalized treatment strategies.
-
Ensemble of Neural Networks: Ensemble learning with neural networks involves combining predictions from multiple neural network models to enhance generalization performance. In cancer diagnosis, ensembles of neural networks are used to mitigate overfitting, improve model robustness, and capture diverse patterns in complex datasets. Ensemble techniques such as bagging, boosting, or stacking are applied to neural network architectures to achieve superior performance in tasks such as tumour classification, survival prediction, or image segmentation.
-
Overall, various types of machine learning models have been employed into the field of oncology. As for specific applications, that is still an emerging field that needs to be further explored.
EXISTING MACHINE LEARNING MODELS IN ONCOLOGY
Machine learning (ML) models are increasingly being applied in oncology to improve various aspects of cancer detection, diagnosis, prognosis, treatment selection, and patient outcome prediction. Some specific examples of machine learning models in oncology:
-
Breast Cancer Detection:
- Deep Learning for Breast Cancer Screening: Researchers have developed deep learning models, particularly convolutional neural networks (CNNs), to analyze mammograms for the early detection of breast cancer. These models can accurately identify suspicious areas, potentially improving early diagnosis and treatment outcomes.
-
Prostate Cancer Diagnosis:
- MRI-Based Radiomics: Radiomics models applied to MRI scans of the prostate have shown promise in distinguishing between benign and malignant lesions. By extracting quantitative features from MRI images, these models can aid radiologists in making more accurate diagnoses and guiding biopsy decisions.
-
Lung Cancer Detection:
- Nodule Detection in CT Scans: ML algorithms have been trained to detect and characterize pulmonary nodules in CT scans, which are indicative of lung cancer. These models can assist radiologists in identifying nodules early, leading to timely interventions and improved patient outcomes.
-
Colorectal Cancer Prognosis:
- Gene Expression Signatures: ML models analyze gene expression data from colorectal cancer patients to predict prognosis and treatment response. For example, a model developed using machine learning techniques identified gene expression patterns associated with high-risk colorectal cancer patients who may benefit from more aggressive treatment strategies.
-
Personalized Treatment Selection:
- Oncotype DX for Breast Cancer: Oncotype DX is a genomic test that predicts the likelihood of breast cancer recurrence and the benefit of chemotherapy in early-stage breast cancer patients. The test uses machine learning algorithms to analyze the expression levels of a panel of genes in tumour tissue, helping oncologists tailor treatment plans to individual patients.
-
Survival Prediction in Glioblastoma:
- Radiomics for Glioblastoma: ML models applied to MRI images and clinical data of glioblastoma patients can predict survival outcomes. By incorporating features extracted from MRI scans and patient demographics, these models offer insights into prognosis and guide treatment decisions for patients with this aggressive brain cancer.
These examples highlight the diverse applications of machine learning in oncology, ranging from early detection and diagnosis to personalized treatment selection and prognosis prediction.
OTHER APPLICATIONS OF MACHINE LEARNING IN ONCOLOGY
Machine learning (ML) is increasingly being employed in various aspects of cancer treatment and research. Here are some other key areas where machine learning is making an impact:
-
Precision Medicine: Machine learning algorithms can analyze genomic data to identify specific genetic mutations associated with different types of cancer. This enables oncologists to tailor treatment plans based on the individual genetic makeup of each patient, leading to more effective and personalized therapies.
-
Drug Discovery and Development: Machine learning algorithms can analyze large datasets of molecular structures and biological pathways to identify potential drug candidates for cancer treatment. This accelerates the drug discovery process by predicting the efficacy and safety of new compounds before they are tested in clinical trials.
-
Treatment Response Prediction: Machine learning models can analyze clinical and genomic data to predict how a patient will respond to different cancer treatments. This helps oncologists choose the most effective treatment plan for each patient, minimizing side effects and improving outcomes.
-
Prognostic Modeling: Machine learning algorithms can analyze various clinical and demographic factors to predict the prognosis of cancer patients. This information helps oncologists identify high-risk patients who may require more aggressive treatment or closer monitoring.
-
Clinical Trial Optimization: Machine learning algorithms can optimize clinical trial design by identifying eligible patients, predicting patient recruitment rates, and optimizing treatment protocols. This accelerates the pace of clinical research and facilitates the development of new cancer therapies.
There are endless applications of Machine Learning technologies within the healthcare field, making it crucial that the opportunities are further explored to optimize potential.
Data
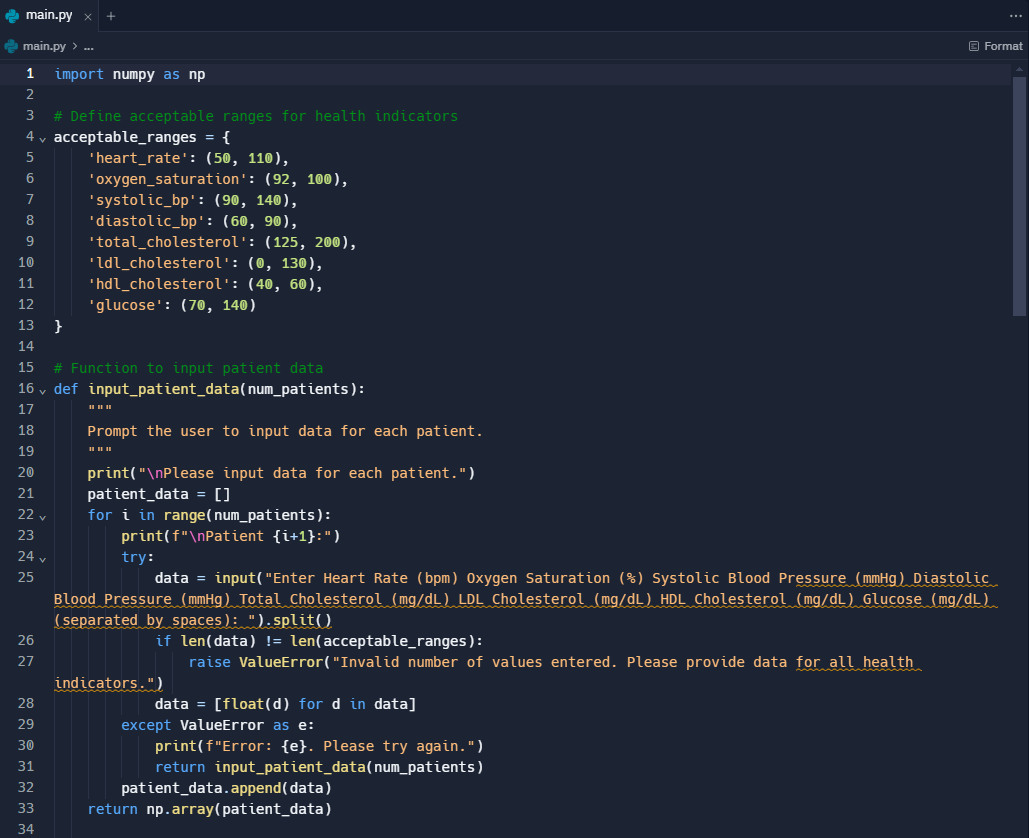
PREDICTIVE MODEL - CODED IN PYTHON
This code implements a matching learning algorithm model for analyzing health indicator data of multiple patients. The algorithm takes as input various health indicators such as heart rate, oxygen saturation, blood pressure, cholesterol levels, and glucose levels for each patient. It then compares these values against predefined acceptable ranges for each health indicator. If any values fall outside the acceptable ranges, the algorithm flags the patient as high risk and identifies the specific health indicator(s) with anomalies.
The model presented in the code is a simplified version of what might be considered a basic anomaly detection system for health indicators. While it provides a functional demonstration of how such a system could work, there are several key differences between this simplified model and a real-world anomaly detection algorithm used in healthcare:
- Feature Engineering and Selection: In a real-world scenario, extensive feature engineering and selection would be necessary to determine which health indicators are most relevant for anomaly detection. This process involves analyzing large datasets to identify meaningful patterns and correlations between various health indicators and health outcomes. Advanced techniques such as dimensionality reduction and feature selection algorithms may be employed to extract the most informative features from the data.
- Statistical Modeling: Real anomaly detection algorithms often employ sophisticated statistical models to characterize the distribution of normal and abnormal data points for each health indicator. These models may include Gaussian distributions, kernel density estimation, or other probabilistic techniques to quantify the likelihood of observing a given data point under normal conditions. Deviations from expected distributions can then be flagged as anomalies.
- Dynamic Thresholding: In practice, the acceptable ranges for health indicators may vary depending on factors such as age, gender, medical history, and comorbidities. Real anomaly detection systems often incorporate dynamic thresholding techniques that adaptively adjust the acceptable ranges based on individual patient characteristics and contextual information. This allows for more personalized anomaly detection and reduces the likelihood of false alarms.
In any case, the model created demonstrates the potential practicality of using Machine Learning in Oncology. Such technologies can offer a valuable tool for healthcare professionals to analyze health indicator data, detect anomalies, and identify patients at risk, ultimately leading to improved patient outcomes and quality of care.
MODEL CODE:
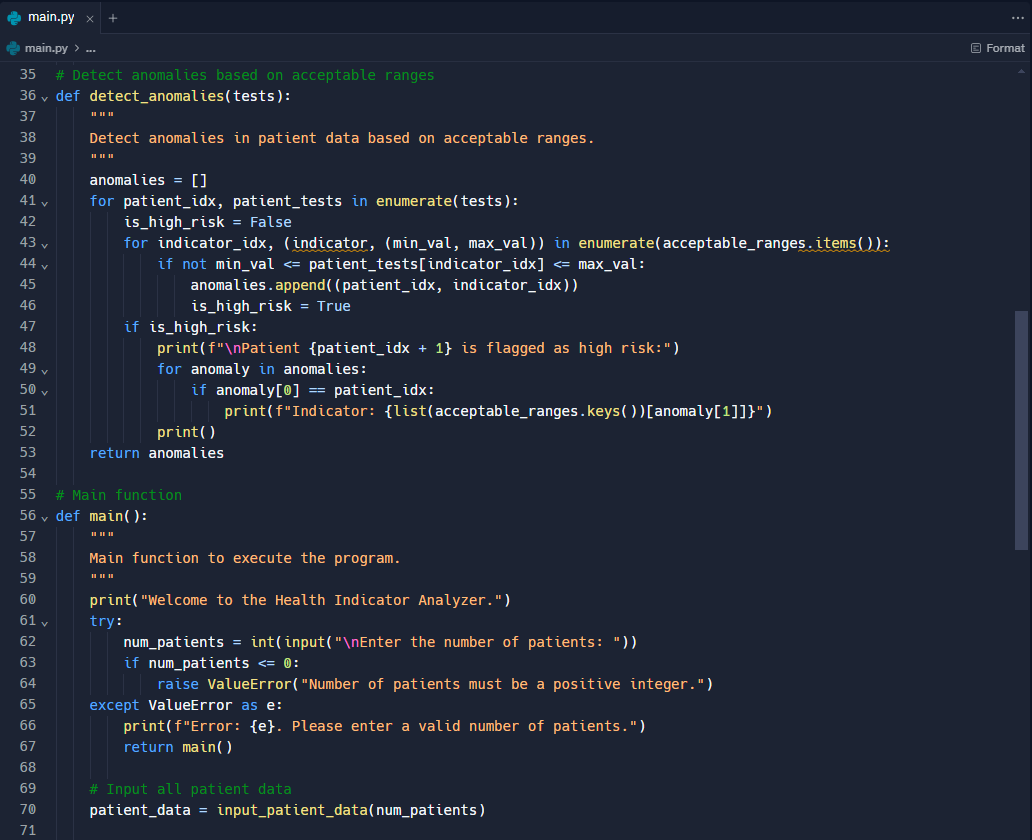
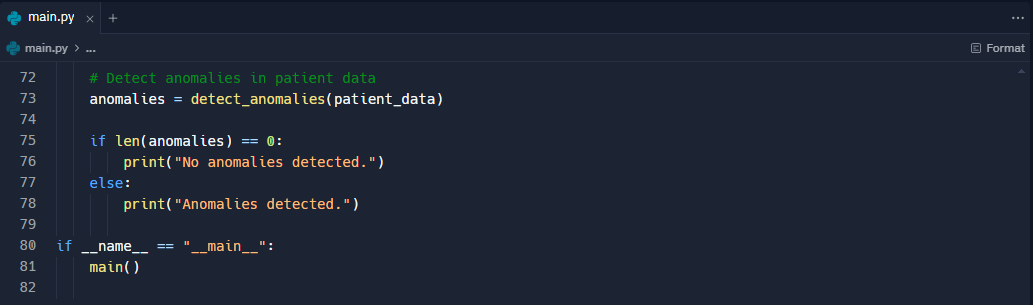
MODEL CONSOLE:
Original Prompt -
After Indicating the Number of Patients -
Overall, this is just a preemptive model. Currently, I am training a network to be able to predict adverse patient outcomes using a tabloid-labelled dataset. This network is still training and will display similar decision making as this model, but will be far more advanced. Will likely be complete for the real fair.
Conclusion
ANALYSIS
PROS OF MACHINE LEARNING IN ONCOLOGY
Machine learning (ML) has several potential advantages in the field of oncology:
- Early Detection: ML algorithms can analyze large datasets of patient information, including imaging scans, genetic data, and patient histories, to identify patterns indicative of early-stage cancer. This can lead to earlier detection and diagnosis, which is crucial for successful treatment outcomes.
- Personalized Medicine: ML models can analyze individual patient data to tailor treatment plans based on a patient's unique genetic makeup, tumor characteristics, and other factors. This allows for more personalized and targeted therapies, potentially leading to better outcomes and reduced side effects.
- Predictive Analytics: ML algorithms can predict disease progression, treatment response, and patient outcomes based on various factors such as tumor genetics, patient demographics, and treatment history. This information can help oncologists make more informed decisions about treatment strategies and prognosis.
- Drug Discovery and Development: ML techniques can accelerate the drug discovery process by analyzing large datasets to identify potential drug candidates, predict their efficacy, and optimize treatment regimens. This can lead to the development of new therapies and repurposing of existing drugs for cancer treatment.
- Image Analysis: ML algorithms can analyze medical imaging data, such as MRI, CT scans, and mammograms, to assist radiologists and oncologists in detecting tumors, assessing their characteristics, and monitoring disease progression over time. This can improve the accuracy and efficiency of diagnosis and treatment planning.
- Data Integration and Decision Support: ML algorithms can integrate data from various sources, including electronic health records, genomic databases, and medical literature, to provide comprehensive patient profiles and decision support tools for oncologists. This can help clinicians stay up-to-date with the latest research and make evidence-based decisions about patient care.
- Cost Reduction: By streamlining processes, improving diagnostic accuracy, and optimizing treatment strategies, ML in oncology has the potential to reduce healthcare costs associated with cancer diagnosis and treatment, ultimately making healthcare more affordable and accessible.
- Research Insights: ML algorithms can analyze large-scale genomic, proteomic, and clinical datasets to uncover new insights into cancer biology, identify biomarkers for early detection and prognosis, and discover novel therapeutic targets. This can accelerate scientific discovery and drive innovation in cancer research.
Overall, machine learning holds great promise for transforming the field of oncology by improving early detection, personalized treatment, patient outcomes, and our understanding of cancer biology. However, it's essential to validate and integrate these ML technologies into clinical practice carefully to ensure their safety, efficacy, and ethical use.
CONS OF MACHINE LEARNING IN ONCOLOGY
While machine learning (ML) has significant potential benefits in medicine, there are also several challenges and potential drawbacks:
- Data Quality and Bias: ML models are highly dependent on the quality and representativeness of the data they are trained on. Biases in the training data, such as underrepresentation of certain demographic groups or clinical conditions, can lead to biased predictions and exacerbate healthcare disparities.
- Interpretability: Many ML models, particularly deep learning models, are often considered "black boxes," meaning it can be challenging to interpret how they arrive at their predictions. Lack of interpretability can hinder clinicians' trust in the model's recommendations and make it difficult to understand the underlying biological or clinical rationale.
- Overfitting and Generalization: ML models trained on specific datasets may perform well on that data but fail to generalize to new, unseen data. Overfitting occurs when a model learns to memorize the training data rather than capturing underlying patterns, leading to poor performance on real-world data.
- Validation and Reproducibility: Ensuring the validity and reproducibility of ML models in healthcare settings is challenging. Models need to be rigorously evaluated on diverse patient populations and tested in real-world clinical settings to demonstrate their effectiveness and generalizability.
- Regulatory and Ethical Concerns: ML algorithms used in medical decision-making must comply with regulatory standards and ethical guidelines to ensure patient safety, privacy, and fairness. Regulatory approval processes for ML-based medical devices can be complex and time-consuming.
- Integration with Clinical Workflow: Integrating ML-based tools into existing clinical workflows can be challenging. Clinicians may face barriers in adopting and using these tools effectively, such as lack of training, time constraints, or resistance to change.
- Malicious Attacks and Security Risks: ML models in healthcare are vulnerable to adversarial attacks, where malicious actors intentionally manipulate input data to deceive the model's predictions. Security risks, such as unauthorized access to patient data or model tampering, also pose significant concerns for ML-based healthcare systems.
- Resource Intensiveness: Developing and deploying ML models in healthcare requires substantial resources, including computational power, expertise in data science and machine learning, and access to high-quality data. Limited resources and expertise may hinder the widespread adoption of ML in healthcare settings, particularly in low-resource or underserved areas.
Addressing these challenges requires collaboration among clinicians, data scientists, policymakers, and regulatory agencies to develop robust and ethically sound approaches for integrating ML into clinical practice while mitigating risks and ensuring patient safety and equity.
FINAL THOUGHTS (CONCLUSION):
In conclusion, the exploration of machine learning (ML) applications in oncology reveals a landscape rich with potential benefits alongside formidable challenges. ML holds promise in revolutionizing cancer care, offering avenues for early detection, personalized treatment, predictive analytics, and groundbreaking research insights. However, the realization of this potential hinges upon addressing significant challenges inherent to ML implementation in clinical settings. Issues such as data quality, bias, interpretability, validation, and regulatory compliance underscore the complexities involved in deploying ML solutions responsibly. Moreover, the integration of ML tools into existing clinical workflows requires meticulous attention to usability, clinician training, and patient safety. Navigating these challenges necessitates collaborative efforts across interdisciplinary teams comprising clinicians, data scientists, policymakers, and regulatory agencies. By fostering a culture of transparency, accountability, and ethical responsibility, stakeholders can work together to develop robust frameworks for the ethical design, validation, and deployment of ML algorithms in oncology. Despite the obstacles ahead, the transformative potential of ML in oncology remains undeniable. Through concentrated efforts to address challenges and leverage opportunities, we can unlock the full spectrum of benefits offered by ML, ultimately enhancing cancer care and improving outcomes for patients worldwide. As we chart the course forward, it is imperative to remain steadfast in our commitment to advancing healthcare innovation while upholding the highest standards of ethics, equity, and patient-centered care.
Citations
- https://www.nature.com/articles/s43856-022-00199-0
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10312208/#:~:text=Machine%20learning%20(ML)%2C%20a,in%20predicting%20cancer%20than%20clinicians.
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8523813/
- https://www.sciencedirect.com/science/article/pii/S2001037014000464
- https://www.cancer.gov/news-events/cancer-currents-blog/2022/artificial-intelligence-cancer-imaging
- https://www.ibm.com/topics/machine-learning
- https://mitsloan.mit.edu/ideas-made-to-matter/machine-learning-explained
- https://www.sas.com/en_us/insights/analytics/machine-learning.html
- https://www.mathworks.com/discovery/machine-learning.html
- https://www.cancer.gov/about-cancer/understanding/what-is-cancer#:~:text=Cancer%20is%20a%20disease%20caused,are%20also%20called%20genetic%20changes.
- https://genomemedicine.biomedcentral.com/articles/10.1186/s13073-021-00968-x
- https://www.sciencedirect.com/science/article/pii/S2666603022000069
- https://news.mit.edu/2022/using-machine-learning-identify-undiagnosable-cancers-0901
- https://www.pennmedicine.org/news/news-releases/2023/january/machine-learning-improves-end-of-life-care-for-cancer-patients
- https://abcnews.go.com/Health/ai-detect-treat-cancer-potential-risks-patients/story?id=101431628
- https://www.mayoclinic.org/diseases-conditions/cancer/diagnosis-treatment/drc-20370594
- https://www.cancer.gov/about-cancer/diagnosis-staging/diagnosis
- https://www.sciencedirect.com/science/article/pii/S2001037021002932
- https://www.sciencedirect.com/science/article/abs/pii/S0006291X15301443
- http://pubmed.ncbi.nlm.nih.gov/37958411/
Acknowledgement
I am deeply grateful to the many individuals who supported me throughout this year's science fair.
First and foremost, I want to thank my family and friends for their unwavering support and encouragement throughout my project.
Next, I would also like to express my gratitude to my teacher, Mr. Buhler, for his invaluable guidance, patience, and dedication in organizing and supervising the science fair for my school.
Lastly, I am indebted to my mentor, Dr. Labib, whose expertise and insight helped me throughout the project. Her guidance not only enriched my understanding of the subject matter but also inspired me to push the boundaries of my research.
In conclusion, I am truly fortunate to have such an incredible support system comprising my family, friends, teachers, and mentors. Their encouragement and assistance have been indispensable, and I am immensely grateful for their contributions to my success in the science fair this year.