
The Future of Martial Arts? A Computerised Judge for Scoring Karate Matches.
Grade 12
Presentation
Problem
Introduction
In the realm of sports and athletics, there are instances where quick and accurate decisions must be made. Taking volleyball, football, and soccer as examples, a proctor determines if there was a foul, a goal, or a misplay. This is especially important in martial arts matches where counting individuals' successful hits decides who wins. Although judges are expected to be impartial, human perception is inherently subjective. Multiple papers ranging from gymnastics, basketball, and karate highlight these different challenges:
- Colour/Shade bias: in elite karate competitions, athletes wearing blue gloves and protective gear are more likely to score than those wearing red [4].
- Conformity bias: judges feel pressured or subconsciously agree to the other decisions [1].
- Reputation bias: judges overestimate the performance of athletes who have a good reputation or previously performed well [1].
- The difficulty of accuracy: especially in gymnastics, analyzing all the details of a performance or action exceeds the cognitive capability of humans. One study finds that the execution of karate techniques ranges from 0.1 to 0.29 seconds [3]. This makes decision-making challenging since humans only have a reaction time of around 0.2-0.4 seconds to a visual stimulus [5].
- National bias: proctors were found to express favoritism to those of the same nationality in muay thai matches [2].
As a martial arts competitor, coach, and judge, I can attest to these biases from personal experience. In some cases, I do doubt my quick decisions similar to point #4 – especially when two individuals “clash” simultaneously, it is difficult to decide who struck first. Secondly, I have first-hand experience with the national bias in #5. Although not a “national” bias, I often see judges award more credit to their students or those under the same martial arts style. These statements are further affirmed by other instructors (with 15+ years of experience) and avid competitors in my martial arts school.
To circumvent these previous challenges, video reviews are a common method to deliver impartial decisions – used by the World Karate Federation, FIFA, FIVB, and other international sports organizations. By utilizing high-definition cameras, officials can review the footage and re-correct or affirm a previous assertion. However, many individuals possess divided opinions about its usage [6, 7]. Firstly, reviewing video footage can take a significant amount of time. This can delay a match further and athletes can feel psychologically affected by the prolonged pause – “it can change the momentum” of the game. Another article [7] states that extensive video replays are “unreasonable” and that “[technology] should not be used to hold players to a higher standard than human beings can reasonably be expected to meet.”. Video reviews can also be expensive to implement with coordination required from both the review panel and camera setup. For this reason, this tool is reserved for only the highest level of competition, excluding local or even provincial events. Lastly, it is important to note that video reviews can only be requested once or twice in many sports. This further exemplifies the reliance on human officials who are subject to biases.
As both a karate black belt and a junior scientist, I wanted to address these challenges (in the context of martial arts) through computers. By developing computer software for scoring, I can create an impartial judge for different contexts. Here, I introduce a prototype system that can possibly used in local tournaments and training to improve fairness in sparring matches.
Method
A Primer on Competition Karate
As mentioned in the problem statement, this project introduces a computer judge for martial arts – more specifically karate. Before moving forward, it is necessary to have a basic understanding of what karate is and its competition formats. Simply put, karate is a martial art originating from Okinawa, Japan that consists of kicking, punching, and striking [8]. In competition, there are two disciplines that individuals compete in:
- “Kata is a demonstration of offensive and defensive movements which are scored by seven judges, who evaluate the kata following the athletic and technical performance of the competitors” [8].
- While sparring or kumite is a match where two individuals face each other in an 8m x 8m area. Like in a fencing match, athletes score points by delivering blows to specific regions of the body: either the head, body, side, or chest areas. If an athlete performs a punch/kick with the correct technique to one of the previously mentioned regions, the match pauses, the judges award a point and both athletes reset positions.

Figure 2.1: An example sparring ring. As shown in the photo, after scoring a point, athletes are required to return to the red starting positions. Obtained from: https://www.youtube.com/watch?app=desktop&v=6qnnxnww7hc
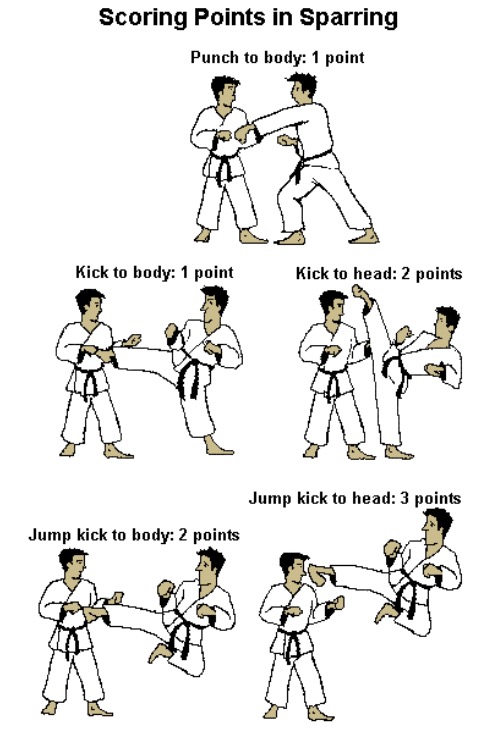
Figure 2.2: Example list of valid contacts: Obtain from: https://martialartslakeville.info/sparring.html
Project Scope
To simplify the development process, the project aims to address the latter of the two: sparring matches. Not only do I find it more interesting, but sparring matches are very dynamic in nature. Teaching or developing an algorithm that can properly classify techniques and determine if they land or not can greatly reduce levels of subjectivity and compensate for the limitations of the human eye. Additionally, I believe it will provide me with a greater learning opportunity than the latter.
Previous Work
Previous research in applying computer vision techniques to karate mainly involves methods used in pose estimation. “Human pose estimation” is the problem of classifying and annotating key points on a person’s body such as their head, shoulder, ankle, or hands [13]. These algorithms make use of “neural networks” that mimic the human brain by using layers of neurons.
Theoretical Background: Neural Networks
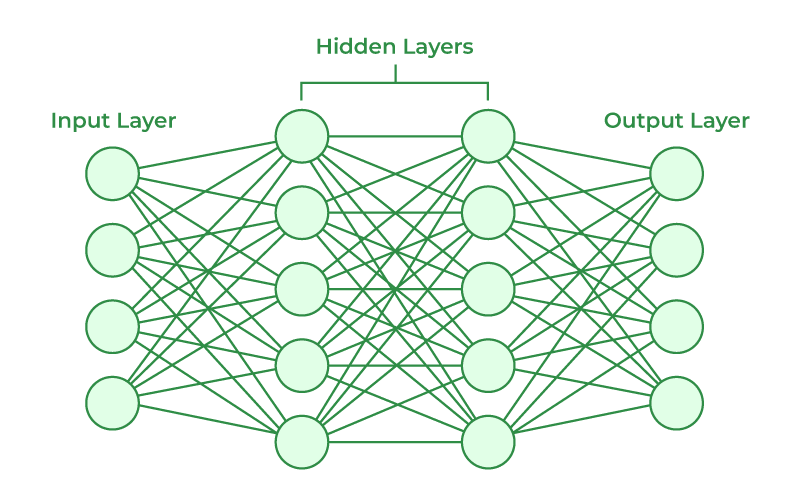
Figure 2.3: A simple 4-layer neural network. Note, that the amount of neurons and hidden layers can vary depending on the provided task. Obtained from [14].
At its foundation, neural networks contain neurons that perform math operations on the input that they receive [14]. In the most basic neural network, there exist layers of neurons that are the “input layer”, “hidden layer” and “output layer”.
- Input Layer:
It is where the neural network receives data that needs to be analyzed.
- Hidden Layer(s):
The data from the input layer is then processed by a series of hidden layers that transform the input into a form that is valuable to the output layer.
- Output Layer:
Finally, using the modified data from the hidden layers, the output layer makes a prediction relevant to the data. If the input is a handwritten digit, then the output layer attempts to guess what number it is.
Theoretical Background: Convolutional Neural Networks (CNNs)
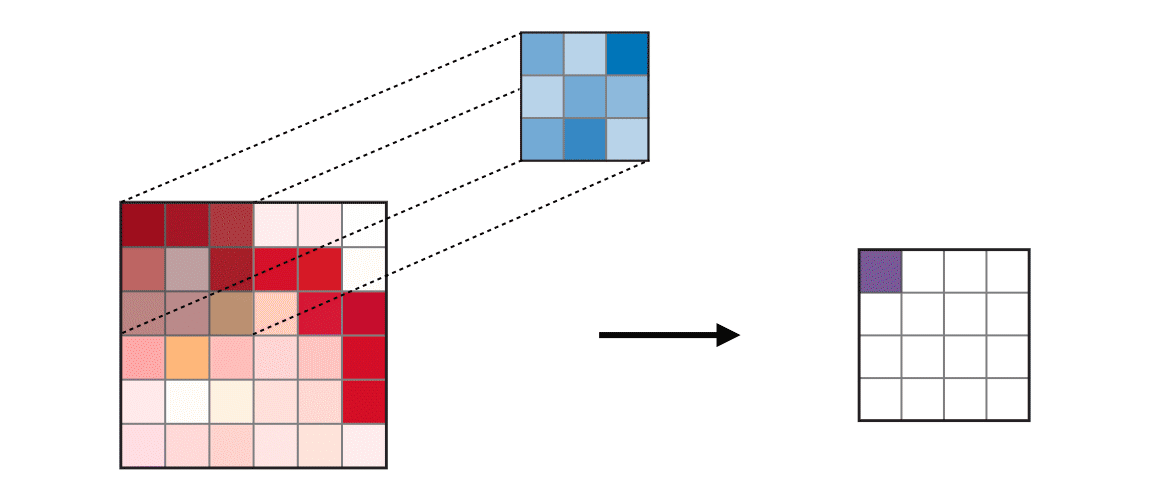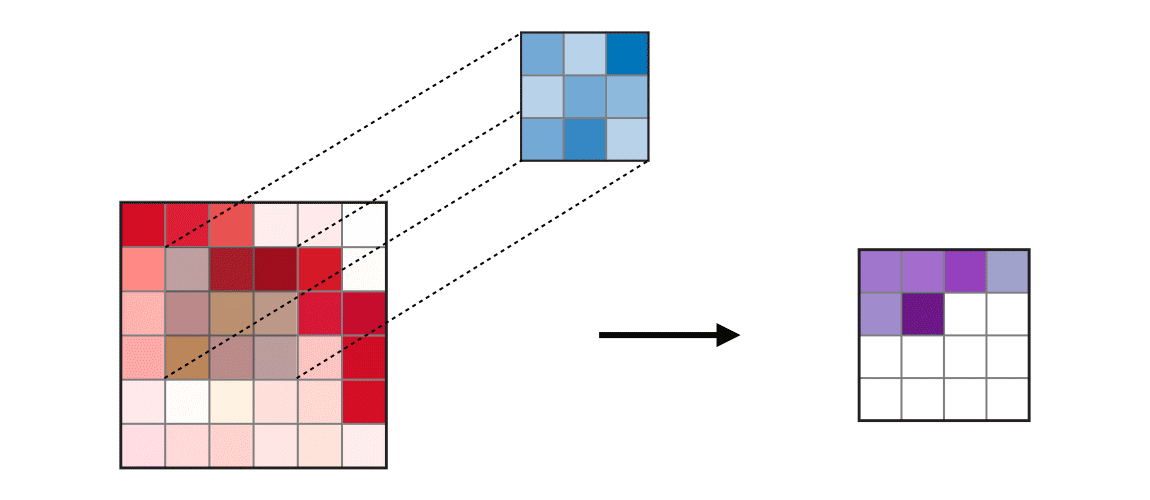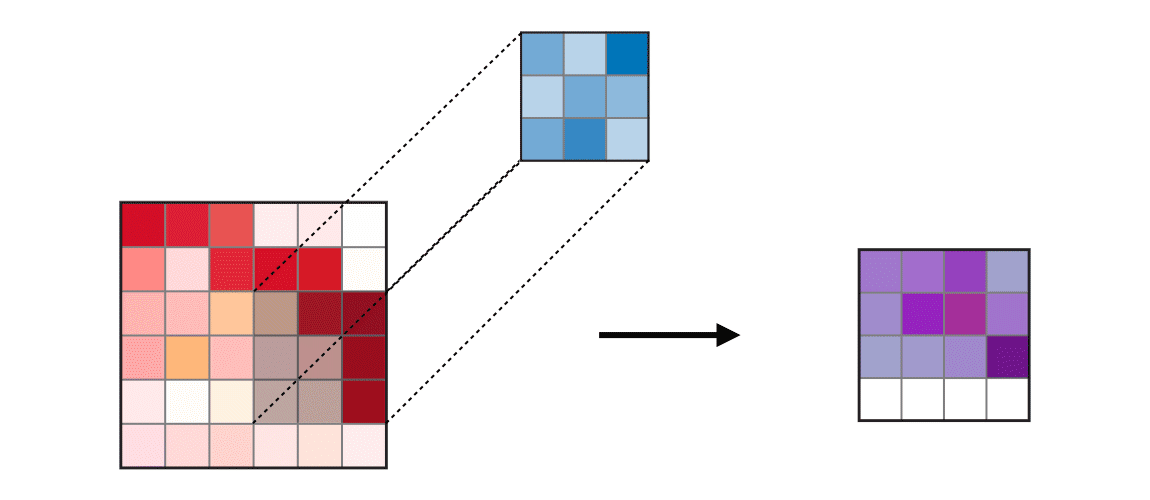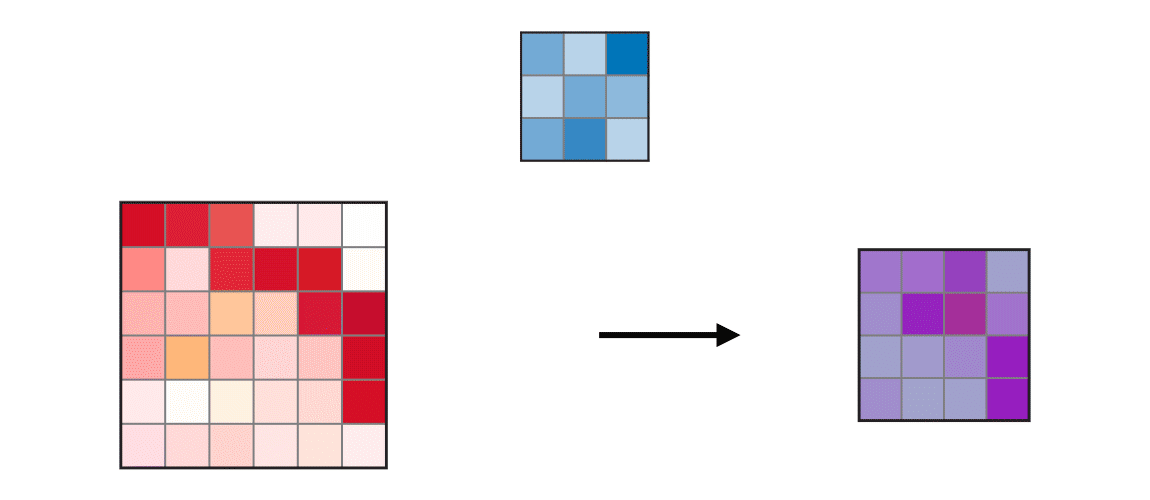
Figure 2.4: Input on the left is multiplied by the kernel (filter), resulting in a feature map -- a smaller version of the input image containing the essential patterns. This compresses the image further, extracting the main features. Obtained from: https://ogre51.medium.com/an-intuitive-introduction-to-convolutional-neural-networks-813cde3d3a5e
Many Pose estimation models employ neural networks but use a variation called Convolutional Neural Networks (CNNs). CNNs make use of the standard neural network structure in addition to filters that imitate the receptive field of an eye [21]. These filters or “kernels” each contain a weight that is multiplied across the entire image and summed -- performing “convolutions”. This creates a feature map or set of smaller images that contains spatial information [19, 20]. These sets of images are converted into another smaller dimension by applying a “max-pooling” layer described in figure 2.6. The compressed output is then used as the input for the next set of operations until it reaches the final layer. In the context of pose estimation, the final layer could be used to output the coordinates of body key points on an image. An example of CNN is highlighted below:
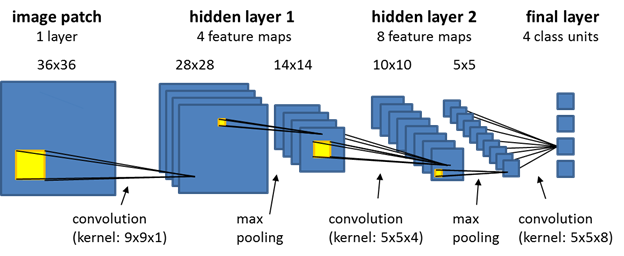
Figure 2.5: An example of CNN architecture. Obtained from: https://doi.org/10.5194/isprs-annals-iv-5-w2-111-2019
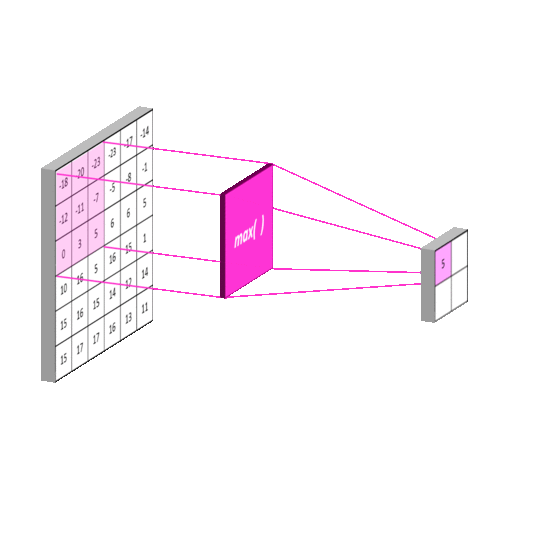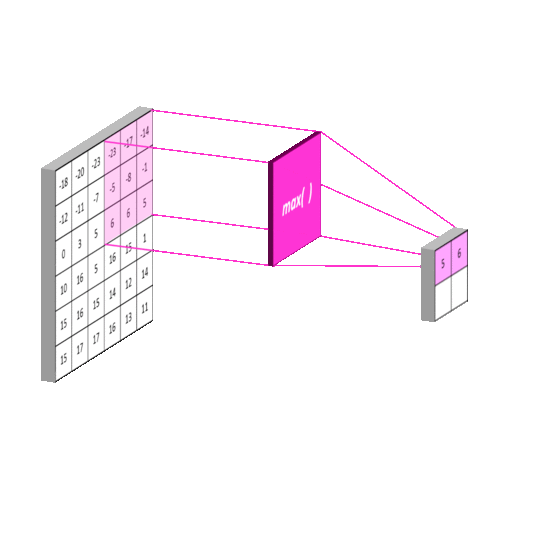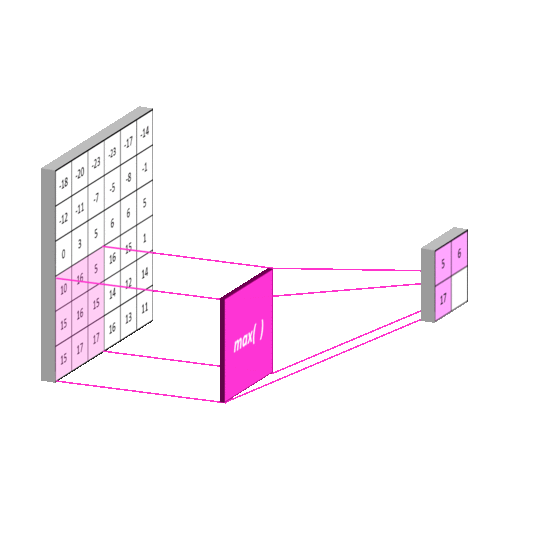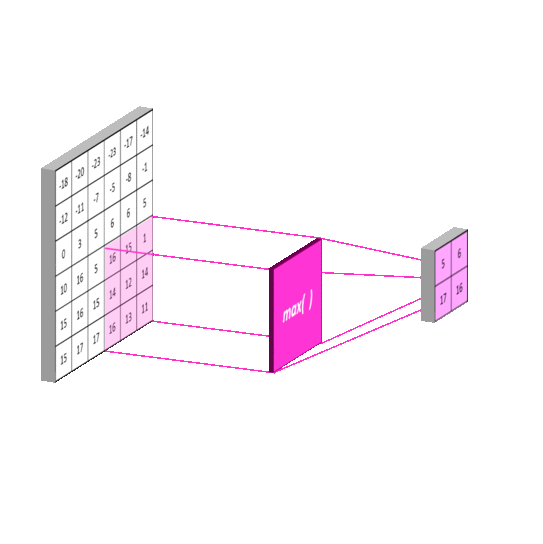
Figure 2.6: Feature maps before and after max pooling. Max pooling takes the maximum value of sections on the feature maps on the left. The result (on the right) is an even more compressed version of these features that represent the essential features of the input. It can be thought of as a “stack of images becomes a stack of smaller images” [20]. Obtained from: https://mlnotebook.github.io/post/CNN1/
Different Pose Estimation Models
Numerous pose estimation models have been introduced by Google and researchers from the University of Washington and Carnegie Mellon. Notable models are OpenPose, PoseNet, MoveNet MediaPipe, and the family of YOLO models. These use a combination of the CNN architecture and regular neural networks to extract key points on a person as in figure 2.7.
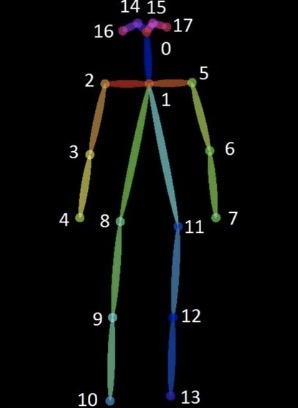
Figure 2.7: Keypoints extracted from models trained on the COCO dataset. Obtained from: https://viso.ai/computer-vision/coco-dataset/
Applications in Karate/Martial Arts
In [9], researchers employed Carnegie Mellon’s OpenPose [11] pose estimation algorithm to extract key points of karate practitioners. These were then processed using another sequential algorithm to classify the poses into different classes of kicks and punches. Other research like [10] used a similar approach, but with Microsoft’s pre-trained Kinect camera [12] – although I considered using these intelligent cameras, I opted not to as they are expensive. One implementation also used the OpenPose algorithm, however, they extracted the angles created by different key points for classification [18].
Other methods for the classification of key points commonly use this idea of angles [17]. In both [15, 16], they employ a similar approach but utilize angles generated from 2D and 3D key points. This adds additional information since there is a sense of depth encoded in the data.
However, up to my current knowledge, there has been no implementation of pose-estimation models for martial arts sparring matches.
Proposed Algorithm
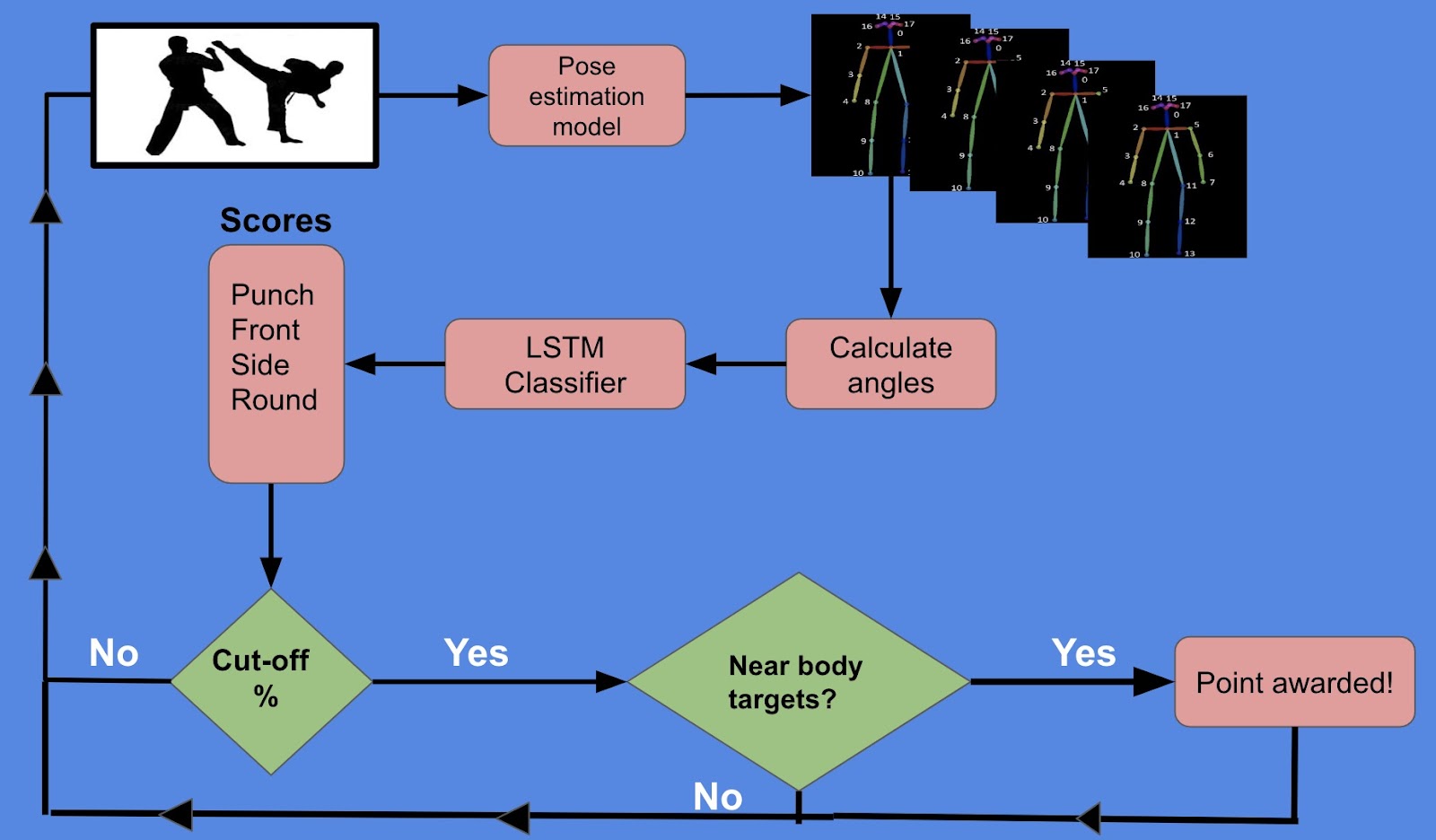
Figure 2.8: Outline of system.
Summary
- Here, using a pose estimation model, I extract the key points for each athlete in the video/live stream.
- Afterwards, I organize a sequence of 30 sets of angles between different key points.
- This sequence is fed towards the sequential LSTM model to classify if the athlete is performing a punch or type of kick. I verify if the athlete has performed a “valid move”.
- After identifying the most confident prediction, I check if it meets a cut-off confidence score of 80%. If it does not meet the cut-off, return to obtaining angles from the image again.
- Lastly, I check if any of the athlete’s hands (for punches) or feet (for kicks) are near the head or inside the opponent’s chest hitbox. If unsuccessful, repeat the process from step 1. If successful, award a point to the athlete.
1) Pose Estimation Model and Angle Calculations
Reviewing previous approaches, I applied the idea of angle calculations paired with a pre-trained pose-estimation model. Referring to figure 2.8, the image is processed by a pose estimation model. For each athlete in the video or live stream, we extract their key points and calculate the angles between them. In total, I calculated 20 angle pairs between different body parts. Additionally, I recorded and arranged 30 sets of these angle-pairs in a sequence – this will be used for classification in 2). The formula for calculating angle-pairs is given below:
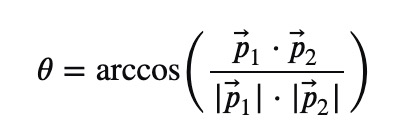
Where:
- The numerator (in the inverse cosine function) is the dot product between two key points from the pose estimator
- The denominator is the product between the magnitude of both key points
Although I could have stored the (x,y) coordinates for each key point on a person, this can be inconsistent for images of different dimensions. Joint (key point) angles are more reliable as they are ratios that do not vary significantly.
2) Long Short-Term Memory Network (LSTM) Classifier
From the sequence obtained from 1), I construct a long short-term memory LSTM classifier. The output of this model checks if the athlete has executed a “valid technique” – either a punch, front kick, roundhouse kick, or sidekick. This is essential since sloppy techniques should not be awarded credit. By verifying they performed an appropriate move, I check if the score reaches a minimum confidence level which adds another layer of filtering.
Theoretical Explanation of LSTMs:
Motions and movements are inherently sequences. LSTMs are often implemented to process data that are sequential or rely on a time dimension [23]. Therefore, they are suitable for analyzing motion: “In an LSTM network, the current input at a specific time step and the output from the previous time step is fed into the LSTM unit, which then generates an output that is passed to the next time step.” [22]. These architectures are advantageous as they possess a “memory” or recollection of previous inputs to influence the calculations for the present output [23].
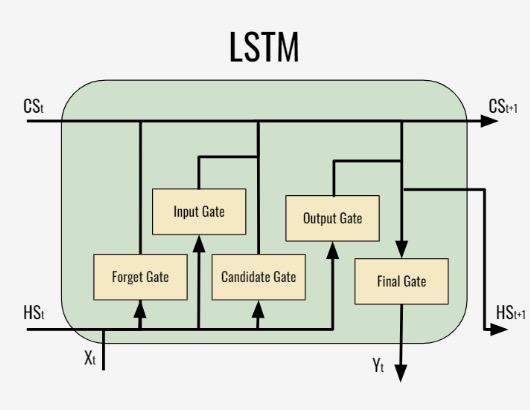
Figure 2.9: Example LSTM Cell. Obtained from: medium.com/mlearning-ai/building-a-neural-network-zoo-from-scratch-the-long-short-term-memory-network-1cec5cf31b7
The LSTM model takes the input xt-1 which could be the first, second, or third input of the sequence. The input goes through five gates and is repeated for all the sequences of the input data:
- Forget Gate: Here, the LSTM decides if it wants to erase its long-term memory (denoted by CSt) with consideration of the short-term memory ( HSt-1) and input xt-1. This memory is particularly useful for adding information to the 100th sequence with the previous context of the 10 sequences prior. The long-term memory is influential at the final gate.
- Input/Candidate Gate: Decides how much the current input, xt-1 will contribute to the new long-term memory ( CSt+1)
- Output/Final Gate: Decide how will the long-term memory CSt+1 affect the short-term memory HSt+1 and the output Yt
Data Gathering and Training for the LSTM
To collect data to train my LSTM model, I obtained videos from YouTube. I manually labeled and collected 25 clips for each of the roundhouse, front, side kicks, and punches. I trained my model on these techniques as they are commonly used in sparring and are elementary. As for my model architecture, I mainly chose arbitrary hyperparameters and layer sizes until my model began to converge. Judges can access model weights and details on my provided Github.
3) Checking Targets
If the output from the LSTM classifier attains the minimum confidence score, I finally check the hands and feet of the athlete. For the athlete to score either the following must occur:
- Either their hand or foot coordinates are within a particular distance to the opponent’s head.
- Either their hand or foot coordinates are within the bounding box generated from their opponent’s shoulders and hips – highlighted below.
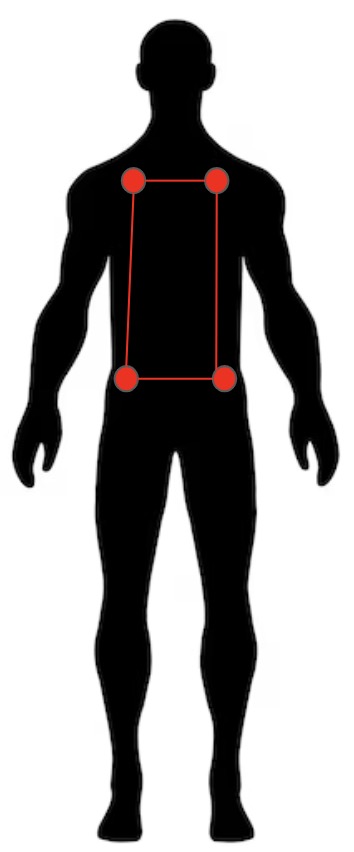
Figure 2.10: An example of the chest bounding box of an individual. For their opponent to score, they must perform a valid technique and have either their head/foot in the polygon or near the head.
Analysis
Link to Project Code: https://github.com/adihatake
Data Collection
To test my algorithm, I collected 30 videos from students at my martial arts school. The participants were either on the school’s competition team or required 5+ years of karate experience. Using a 30 FPS and 1080 resolution camera, I recorded sparring matches during their regular hours of training. The results of my testing
Challenge 1: False Positives
One of the initial problems I encountered with my algorithm was that it was inconsistent with its predictions. Namely, in that it was giving high confidence scores to moves that did not truly occur. To resolve this issue, I created another class of movements called “nothing” as negative samples. Thus, if the model predicted nothing, then no scoring calculations should occur. Overall, this drastically improved the viability of my model and prevented false positives.
Challenge 2: Athlete Tracking
Since athletes are constantly moving, there are instances where they are occluded and not visible to the camera. These were challenges experienced when I utilised Google’s Mediapipe model. As a result, I switched to Ultralytic’s Yolov8 model. Not only did it improve tracking, but the inference time was lessened.
However, the disadvantage of this switch was that the Yolov8 model outputted 2D coordinates as opposed to 3D coordinates seen with the Mediapipe model. This resulted in challenge 3 and 4.
Challenge 3: Drop in Accuracy for the LSTM Classifier
Another challenge I experienced was a decrease in accuracy from both the Mediapipe and Yolov8 model. I theorised this could be due to the limited size of my training dataset, but also the switch from calculating angles in 2D instead of 3D coordinates. To address this, I turned to data augmentation techniques to artificially increase my training files. By adding or subtracting 5 and 2.5 degrees from each example, I tripled the size of my dataset. This had a positive impact on the validation accuracy.
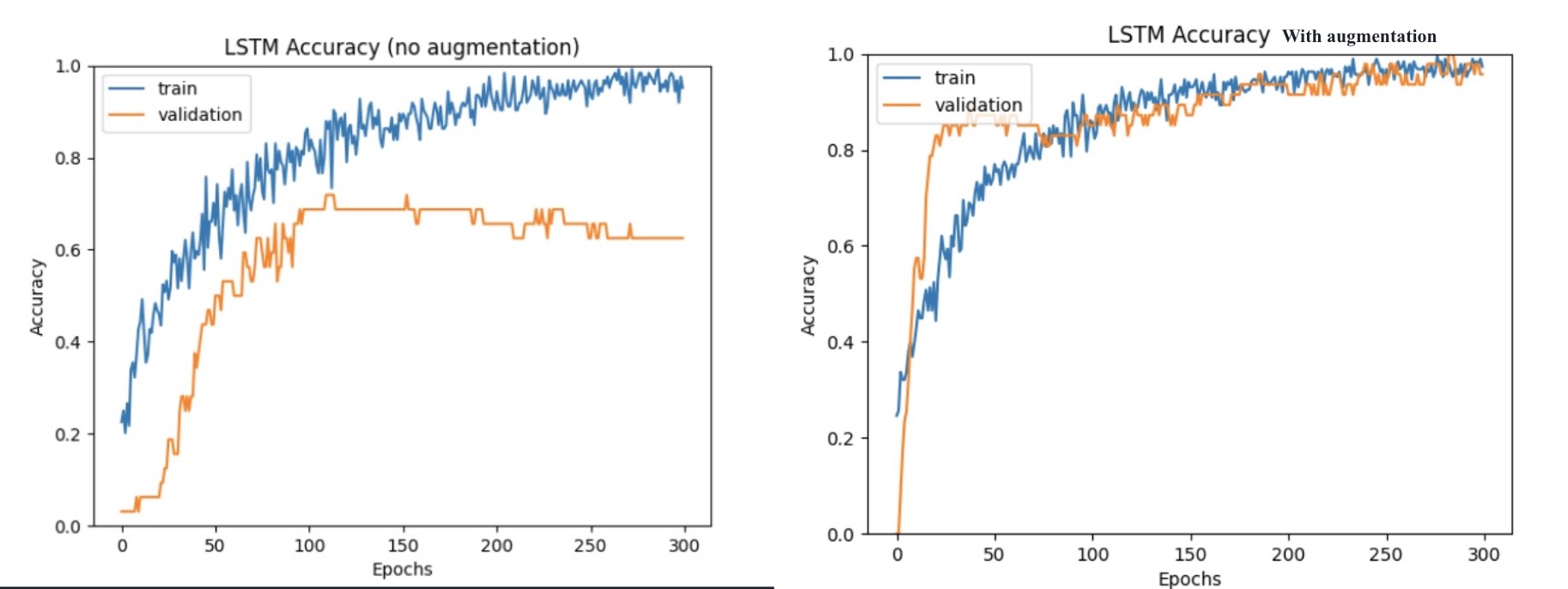
Figure 3.1: Learn curves of the LSTM model with and without data augmentation
Challenge 4: Able to Identify Punches but not Kicks
Despite the previous measures, the switch to the Yolov8 model resulted in more incorrect classifications for the kicks. As seen in the above image, there are instances where the Yolov8 model does not precisely predict the keypoints. Compared to punches that focus mainly on the arm, kicks are inherently more complex as they involve more movements and variations. The lack of 3D key points from the Yolov8 could have also contributed to the misclassification.
Challenge 5: Distancing and Polygon Logic
A limitation of Yolov8, is that it identifies wrists and ankles, but not so much the extremities of the hands and feet. Although athletes did land hits, the algorithm was unable to register them, because the estimated key points are too far from the contact point.
Due to these numerous inconsistencies, I abandoned the polygon logic and opted for a distance threshold between the athlete’s hand/foot and the target key points like the head, hip and shoulder. This worked in some cases, but is quite inaccurate when both athletes are occluded. It could be that the distance between these points is quite small and causes flaws in the logic.
Conclusion
Considering this project as a whole, I achieved partial success in creating a scoring system that evaluates sparring matches. My algorithm was capable of correctly identifying hits with punches but requires additional research to circumvent the effects of occlusion and model selection.
Aside from the Yolov8 and Mediapipe models, some pose-estimators were not tested due to the interest of time and computation resources. It would greatly benefit my project to implement these other models.
Additionally, to propel this project forward, multiple avenues for future exploration present themselves:
- - Multiple Camera Angles: Incorporating data from multiple camera angles can enhance the system's ability to capture and analyze sparring activity comprehensively. Additionally, it has the potential to combat the effects of occlusion that plagued my system.
- - Expanded Training Data: Augmenting the dataset with more diverse classes and instances will bolster the model's robustness and adaptability across various sparring scenarios. By gathering more data, I can also analyze more sparring techniques like hook kicks, sweeps and fakes.
- - Game Trees Development: By classifying which techniques athletes use, I can construct trees that demonstrate which series of moves earns them points. If I can construct a graph with the executed techniques and whether they scored or not, I can perhaps apply a path-finding algorithm. The result would be the most optimal series of moves an athlete can take. Ultimately, this would greatly benefit coaches and athletes to improve their skill set.
In essence, while this project marks a significant step forward in sparring match evaluation, it also lays the groundwork for continued refinement and innovation in this domain. Through ongoing research and development, the envisioned scoring system can evolve into a valuable tool for trainers, athletes, and spectators alike.
Citations
[1] Heiniger, S. & Mercier, H. (2021). Judging the judges: evaluating the accuracy and national bias of international gymnastics judges. Journal of Quantitative Analysis in Sports, 17(4), 289-305. https://doi.org/10.1515/jqas-2019-0113
[2] Myers, Tony D et al. “Evidence of nationalistic bias in muaythai.” Journal of sports science & medicine vol. 5,CSSI 21-7. 1 Jul. 2006
[3] Carlsson, Tomas & Berglez, Jozef & Koivisto, Sebastian & Carlsson, Magnus. (2020). The impact of video review in karate kumite during a Premier League competition. International Journal of Performance Analysis in Sport. 20. 1-11. 10.1080/24748668.2020.1794258.
[4] Berglez, Jozef & Arvidsson, Daniel. (2023). Impact of the color of equipment on competition outcomes in Premier League karate. Ido Movement for Culture. 23. 22-27. 10.14589/ido.23.2.4.
[5] Jain, Aditya et al. “A comparative study of visual and auditory reaction times on the basis of gender and physical activity levels of medical first year students.” International journal of applied & basic medical research vol. 5,2 (2015): 124-7. doi:10.4103/2229-516X.157168
[6] Levy, D. (2017, October 3). Is replay review helping sports or helping to ruin sports?. Bleacher Report. https://bleacherreport.com/articles/2036386-is-replay-review-helping-sports-or-helping-to-ruin-sports
[7] Peter Shawn Taylor May 7, 2017. (2017, July 6). Video replay is ruining professional sports. Macleans.ca. https://macleans.ca/sports/video-replay-is-ruining-professional-sports/
[8] WKF - World Karate Federation. Olympics. (n.d.). https://olympics.com/ioc/world-karate-federation
[9] Ait Bennacer, Fatima-Ezzahra & Aaroud, Abdessadek & Khalid, Akodadi & Cherradi, Bouchaib. (2022). Applying Deep Learning and Computer Vision Techniques for an e-Sport and Smart Coaching System Using a Multiview Dataset: Case of Shotokan Karate. International Journal of Online and Biomedical Engineering (iJOE). 18. 10.3991/ijoe.v18i12.30893.
[10] Emad, Bassel & Atef, Omar & Shams, Yehya & El-Kerdany, Ahmed & Shorim, Nada & Nabil, Ayman & Atia, Ayman. (2020). iKarate: Improving Karate Kata. Procedia Computer Science. 170. 466-473. 10.1016/j.procs.2020.03.090.
[11] Cao, Z., Hidalgo, G., Simon, T., Wei, S., & Sheikh, Y. (2018). OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43, 172-186.
[12] Azure Kinect DK – develop AI models: Microsoft Azure. – Develop AI Models | Microsoft Azure. (n.d.). https://azure.microsoft.com/en-ca/products/kinect-dk
[13] Pose estimation. Papers With Code. (n.d.). https://paperswithcode.com/task/pose-estimation
[14] GeeksforGeeks. Artificial Neural Networks and its Applications. GeeksforGeeks [Internet]. 2023 Jun 2; Available from: https://www.geeksforgeeks.org/artificial-neural-networks-and-its-applications/
[15] Reid, S., Coleman, S., Kerr, D. et al. Keypoint Changes for Fast Human Activity Recognition. SN COMPUT. SCI. 4, 621 (2023). https://doi.org/10.1007/s42979-023-02063-x
[16] Yadav, S.K., Tiwari, K., Pandey, H.M. et al. Skeleton-based human activity recognition using ConvLSTM and guided feature learning. Soft Comput 26, 877–890 (2022). https://doi.org/10.1007/s00500-021-06238-7
[17] Vrigkas, M., Nikou, C., & Kakadiaris, I. A. (2015). A review of Human Activity Recognition Methods. Frontiers in Robotics and AI, 2. https://doi.org/10.3389/frobt.2015.00028
[18] Echeverria, J., & Santos, O. C. (2021). Toward modeling psychomotor performance in karate combats using Computer Vision Pose Estimation. Sensors, 21(24), 8378. https://doi.org/10.3390/s21248378
[19] Shiri, Farhad Mortezapour, et al. "A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU." arXiv preprint arXiv:2305.17473 (2023).
[20] Rohrer, Brandon. “How Convolutional Neural Networks Work, in Depth.” YouTube, YouTube, 17 Oct. 2018, www.youtube.com/watch?v=JB8T_zN7ZC0.
[21] Amini, Alexander. “MIT Introduction to Deep Learning: 6.S191.” YouTube, 10 Mar. 2023, youtu.be/QDX-1M5Nj7s?si=_ZnIC4Og52MtXxLO.
[22] Shiri, Farhad Mortezapour, et al. "A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU." arXiv preprint arXiv:2305.17473 (2023).
[23] “What Are Recurrent Neural Networks?” IBM, www.ibm.com/topics/recurrent-neural-networks. Accessed 27 Feb. 2024.
Acknowledgement
I would like to thank my parents for supporting me throughout this project; from buying me materials and brainstorming ideas, thank you so much.
Secondly, I would like to thank Mrs. Pollard for facilitating and aiding me through the registration process. Thank you for the past 3 years.
Lastly, I would like to thank my friends and colleagues at Capicio Zen Karate for assisting me with testing my project -- without this testing, I would haven't able to realize this project.